こんにちは KEYチームの円城寺です。
せっかく Atlassian Expert なので Atlassian の記事を書いてみよう第2弾ということで、
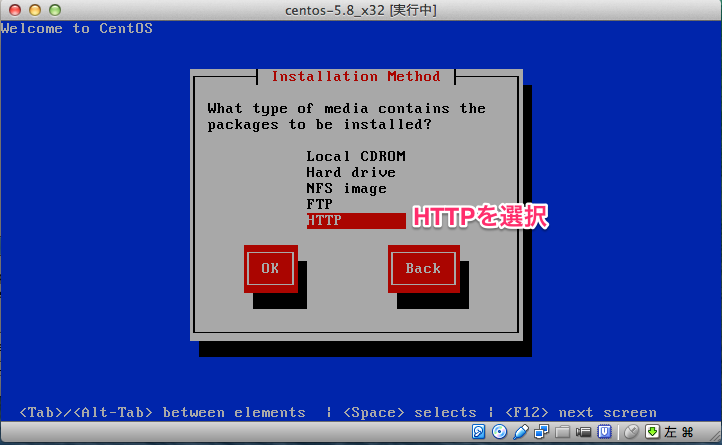
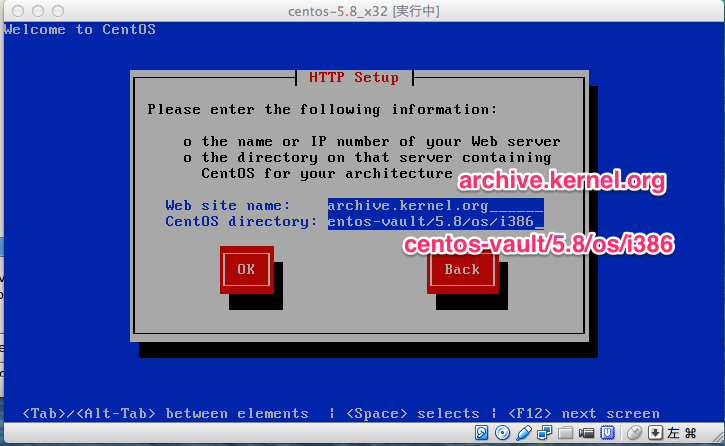
今回は Crowd サーバーのインストールをしてみます。
下記の環境に Crowd をインストールしていきたいと思います。
- OS : CentOS 7
- Java : OpenJDK 1.7
- mariadb : 5.5
- Atlassian : Crowd 2.8
K. 仮想環境の準備
今回は
予算の都合上
実験ということで、MacOSX 上の「VirtualBox+Vagrant」の仮想環境に環境を構築します。
専用のサーバーを用意されている方はこの部分は読み飛ばして頂いて結構ですが、
気軽に壊せる環境というのも便利ですので、今回の実験用に試しに構築してみるのもよろしいかと思います。
Virtualbox のインストール
Virtualbox の以下サイトより、お使いのプラットフォームに合わせたバイナリをダウンロードして、セットアップしてください。
https://www.virtualbox.org/wiki/Downloads
Vagrant のインストール
Vagrant の以下サイトより、お使いのプラットフォームに合わせたバイナリをダウンロードし、セットアップしてください。
https://www.vagrantup.com/downloads.html
VMの準備
1. vagrant box を準備する
$ vagrant box add centos7.0 [任意のCentOS7のBoxファイルURL]
$ mkdir crowd
$ cd crowd
$ vagrant init centos7.0
2. Vagrantfile の下記部分のコメントを外して、内部IPで通信できるようにする
config.vm.network "private_network", ip: "192.168.33.10"
3. VM を起動する
$ vagrant up
これでひと通り仮想環境の準備は完了です。
E. Crowd のインストール
さて、環境も整いましたので、いよいよ Crowd のインストールと参ります。
前提条件の準備
早速 Crowd をインストールといきたいところですが、Crowd を動かすための前提ソフトウェアをまずインストールしましょう。
1. Java のインストール
まずは Java をインストールします。
今回は yum で簡単にインストールできる OpenJDK を使用しましたが、
Oracle の JDK(こちらのほうが無難という噂もあり)をご使用される場合は適宜インストールをお願いします。
$ sudo yum install java-1.7.0-openjdk
2. mariadb のインストール
次に Crowd のデータ保存先であるデータベースのインストールです。
今回は MySQL ではなく、CentOS7 系なので、mariadb を使用します。
$ sudo yum install mariadb-server
3. mariadb の起動
$ systemctl start mariadb
Crowd のインストール
さて、とうとう Crowd のインストールです。
基本的には 公式ドキュメント( https://confluence.atlassian.com/display/CROWD/Installing+Crowd )にそってインストールを行っていきます。
1. 最新版のダウンロード
まずは、以下公式サイトより最新版をダウンロードします。
https://www.atlassian.com/software/crowd/download
今回は Crowd Standalone 版をダウンロードします。
$ wget http://www.atlassian.com/software/crowd/downloads/binary/atlassian-crowd-2.8.0.tar.gz
2. 展開と配置
次にダウンロードしたバイナリを Crowd のインストール先ディレクトリに展開します。
今回は便宜上、
- Crowd のインストール先を /opt/atlassian/
- crowd home を /var/atlassian/crowd
としていますので、 /opt/atlassian にダウンロードしたバイナリを展開します。
$ tar -xf atlassian-crowd-2.8.0.tar.gz
$ sudo mkdir /opt/atlassian
$ sudo mv atlassian-crowd-2.8.0 /opt/atlassian/
$ sudo ln -s /opt/atlassian/atlassian-crowd-2.8.0 /opt/atlassian/crowd
3. crowd home の準備
次に、Crowd のデータ保存先になる crowd home を準備します。
$ sudo mkdir -p /var/atlassian/crowd
4. 設定ファイルの編集
次に、Crowd の環境依存部分の設定を設定ファイルに設定します。
対象のファイルは以下。
${crowdインストール先}/crowd-webapp/WEB-INF/classes/crowd-init.properties
このファイルの crowd.home を下記のように先ほど作成したディレクトリに変更します。
crowd.home=/var/atlassian/crowd
Crowd 用データベースの準備
次に Crowd のデータ保存先であるデータベースを準備します。
1. データベースの作成
create database crowd character set utf8 collate utf8_bin;
2. Crowd ユーザーを作成し、権限を付与
GRANT ALL PRIVILEGES ON crowd.* TO 'crowduser'@'localhost' IDENTIFIED BY 'crowdpass';
3. Crowd 用に mariadb に設定を追加
/etc/my.cnf の[mysqld]セクションに以下の4設定を追加
[mysqld]
---中略---
character-set-server=utf8
collation-server=utf8_bin
default-storage-engine=INNODB
transaction-isolation = READ-COMMITTED
4. mariadb(mysql)の Java ドライバをインストール
$ yum install mysql-connector-java.noarch
$ cp /usr/share/java/mysql-connector-java.jar /opt/atlassian/crowd/apache-tomcat/lib/.
Y. Crowd の起動
さて、準備が整いましたので、Crowd を起動してみます。
Crowd の起動
$ cd /opt/atlassian/crowd/
$ ./start_crowd.sh
Crowd の初期設定
1. Crowd 初期設定画面へアクセスする
Crowd の初期設定画面 http://localhost:8095 にアクセスします。
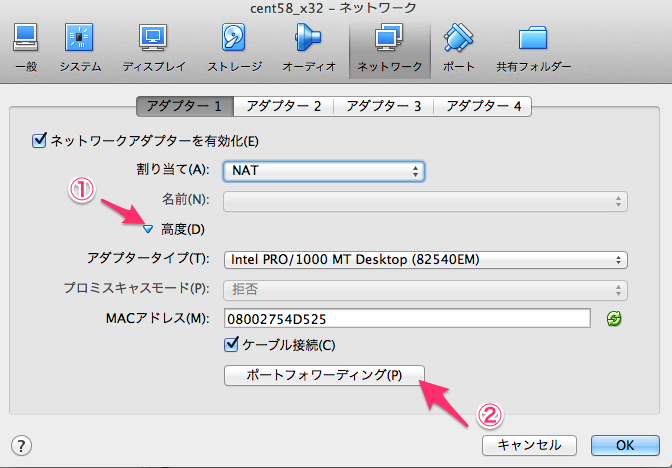
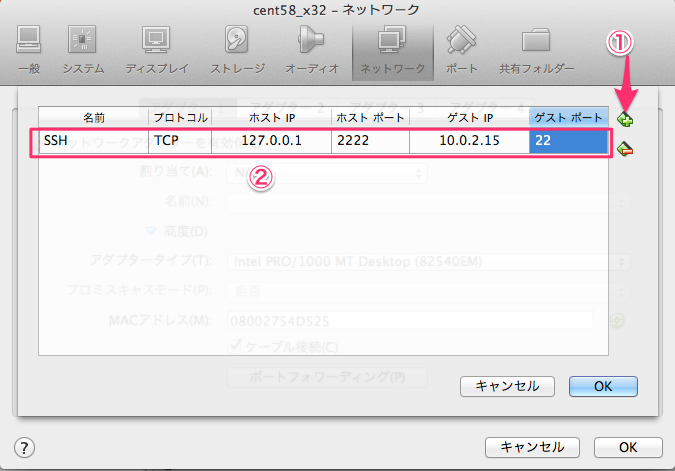
設定画面へは、Crowd のサーバー上からしかアクセス出来ないようなので、
別サーバーからつなぐ場合は SSH トンネルなどを用意します。
(例)
$ ssh vagrant@192.168.33.10 -i ~/.vagrant.d/insecure_private_key -L 8095:localhost:8095
初期設定画面にアクセス出来た後は、画面の指示にしたがって必要な情報を入力してゆきます。
以降は今回の設定例です。必要に応じで参考にしてください。
あくまでテスト用の設定ですのでご注意ください。