


KEY チームのアライです。
HP リニューアル後、atlassian ページが無くなっていましたが、いよいよ再開させます。
もう少々お待ちください!
ブログやページ内で各製品の事例などもお届けしていきます。
過去の Atlassian 関連ブログはコチラ↓
Featured










KEY チームのアライです。
HP リニューアル後、atlassian ページが無くなっていましたが、いよいよ再開させます。
もう少々お待ちください!
ブログやページ内で各製品の事例などもお届けしていきます。
過去の Atlassian 関連ブログはコチラ↓
みなさん、こんちには。KEYチームの矢納です。
頑張って技術ネタを連続で投稿していこうと思っています。
過去記事の目次はこちらに移動しました。
今回はApacheでProxyを行う方法です。よくこの関連記事は見るのですが、毎回忘れてしまうのでここに残します。
今回はCentOS7にインストールします。
# yum -y install httpd
自動起動の設定を追加し、Apacheの起動です。
# systemctl enable httpd.service
# systemctl list-unit-files | grep httpd
httpd.service enabled
# systemctl start httpd
httpd.confでProxyのmoduleを有効にする。 httpd.confは今回/etc/httpd/confにありました。
#LoadModule proxy_module modules/mod_proxy.so
#LoadModule proxy_ajp_module modules/mod_proxy_ajp.so
この2行のコメントアウトを外す
とおもっていたのですが、56行目が
Include conf.modules.d/*.conf
となっています。 なので/etc/httpd/conf.modules.d/のディレクトリの中を覗いてみました。
-rw-r--r-- 1 root root 3739 Mar 12 14:57 00-base.conf
-rw-r--r-- 1 root root 139 Mar 12 14:57 00-dav.conf
-rw-r--r-- 1 root root 41 Mar 12 14:57 00-lua.conf
-rw-r--r-- 1 root root 742 Mar 12 14:57 00-mpm.conf
-rw-r--r-- 1 root root 894 Mar 12 14:57 00-proxy.conf
-rw-r--r-- 1 root root 88 Mar 12 14:57 00-systemd.conf
-rw-r--r-- 1 root root 451 Mar 12 14:57 01-cgi.conf
たくさんありました(^^; 上記の二つのモジュールを有効にする必要が有るので検索です。
# grep -e mod_proxy.so -e mod_proxy_ajp.so *
00-proxy.conf:LoadModule proxy_module modules/mod_proxy.so
00-proxy.conf:LoadModule proxy_ajp_module modules/mod_proxy_ajp.so
あれ?最初から有効になっていますね。
Proxyの設定をhttpd.confに追加しましょう。
ProxyPass /static !
ProxyPass /api http://localhost:8080/twm
ProxyPassReverse /api http://localhost:8080/twm
この設定は
CORS(Cross-Origin Resource Sharing)を避けるためによくProxyを使って回避するのですが、一度設定してしまえばもう見ることのない部分です。また、他の人が設定してしまえばさらに見ることはかなり減ってしまいます。
そのようなわけでよく忘れてしまうのです(^^;
Email: yanou at atware.co.jp
Atlassian社製のCI(継続的インテグレーション)/CD(継続的デリバリー)を実現するソフトウェアであり、同様のソフトウェアにはJenkinsやCircleCI、TravisCIなどが存在します。
今回は、そんなBambooをセットアップし、ユーザー管理を以前紹介したCrowdに統合する方法をご紹介したいと思います。
これにより、システム管理者、運用者の負荷を軽減してくれるBamboo。それ自体の管理負荷を下げて、より生産的で楽しいことに注力できるようにしたいと思います。
今回は、前編として、Bambooのインストール方法をご紹介させて頂きます。
基本的には公式手順にのとって進めていきます。
ダウンロードしたBambooのアーカイブを展開し、配置します。
マニュアルに記載のある通り /opt/atlassian/bamboo/atlassian-bamboo/WEB-INF/classes/bamboo-init.properties を以下の様に修正します。
bamboo.home=/var/atlassian/application-data/bamboo
/opt/atlassian/bamboo/bin/setenv.sh のメモリ設定を任意の値に変更します。 最大1GB程度にしておけばひとまず問題ないと思われます。
次にデータ保存先であるデータベースを準備します。 今回はBambooのデータ保存先としてcrowdインストール編で用意したMySQL(MariaDB)を使用します。
Mysqlのドライバを予めBamboo配下に配置しておきます。
/opt/atlassian/bamboo/lib
以下に ドライバのjarファイルを配置しておきます。
ひとまず起動します
http://{bambooインストールIP}:8085/ にアクセスすると、 初期設定画面が表示されるので、画面に従って初期設定を行います。
事前に用意してあればそのライセンスキーを入力します。 評価用であればAtlassian公式サイトよりトライアルキーが取得出来ますので、それを入力します。
通常であれば変更の必要がないため、そのままContinueします。
Bambooのデータを保存するデータベースを選択します。 今回はMySQLに保存するため、MySQLを選択しContinueします。
データベースの準備で作成したデータベースへの接続パラメータを入力しContinueします。 Continueを押すと、データベースの初期設定が始まります。 しばらく時間がかかるので、根気よく待ちましょう。
今回は新規インストールですので、「Createa new Bamboo home」を選択しContinueします。
任意のIDとパスワードで管理ユーザーを作成します。
以上で、Bambooのインストールは完了です。 次回は、以前インストールしたCrowdとBambooを連携させて、ユーザー管理をCrowdに統合したいと思います。
こんにちはKEYチームの荒木です。今月もブログを書いたので読んでいただけたら嬉しいです。
開発者としてプロジェクトマネージャーとしていくつかのプロジェクトに関わってきました。 そして、この世界に入ってからずっと現役でコードを書き続けると思っていました。しかし、2014年6月に会社の変革と自らの気持ちが一致して、チームの管理を行うチームリーダーに自らなることを決断しました。
リーダーとして1年やってきた経験を2回に分けてお伝えしたいと思います。
チームリーダーの仕事は思っている以上に大変です。向き不向きがあるかもしれません。 リーダーに求められていることは何でしょう?
一言でいうと結果を出すことです。
チームの開発能力を高くしても、結果が出なければリーダーとしてはダメです。メンバーのモチベーションを高め、最新の技術やプロセスを駆使して、時には怒り、時には褒め、苦渋の決断を下し、方針を決定しながらチームとして結果を出し続けなければなりません。失敗は常にリーダーの責任になります。そして、成果はメンバー全員の努力のおかげです。
結果を出すことに動機がなければ続けられないです。つまり、チームへ仕事への愛が必要です。
結果をだすために重要と感じたこと3点。
1つ目は良きメンバー(パートナー)にであうことです。 困難なときに問題はリーダーだけでは解決できません。仲間と共に協力して行く必要があります。 人間関係が大切で、結果を左右することだと、理解しておく必要があると思います。
2つ目はチャレンジし続け前に進むことです。 チャンスはいたるところにあります。怖がらずにチャレンジし続け、全力でぶつかった人にだけしか成功は訪れないと思いました。最初はほんの僅かの可能性だけかも知れません。ですが、そのほんの僅かの可能性を信じ、行動し、少しでも状況を変えられたとしたら、それってもう結果に向かって進んでいるんだと思います。
3つ目は謙虚であることです。 常に自分に問題があるかもしれないと思い自分が正しいと思いすぎないことです。
リーダーになりたての頃は、メンバーに何を話したらいいのか分かりませんでした。伝え方が悪かったり、しゃべりすぎたり、いろんな失敗をしてきました。メンバーへの遠慮もありました。他のリーダーとも会話もまったくなく意見交換もありませんでした。
その思いをリーダー達に伝えましたが他のリーダーには響かなかったようで孤独感が襲ってきました。
その後、あるリーダーがチームの課題を素直にオープンにしました。その決断は素晴らしく、チームのコンセンサスが取れていない状態をオープンにして自信をなくしていることを伝えているのだと感じました。それからは他のリーダーとも時折会話するようになり共有を図るようになりました。
伝え方は千差万別。どのように伝えるかは難しいです。共有を図ることで成功させる可能性を上げることができます。
このことから学んだことは、話し方の重要性と機が熟していないタイミングで話をしても無視されることです。もし無視されていたら機を熟させる方法を考えることにしました。
続きはこちらです。
みなさん、こんにちは。lunettesチームの的場です。 今回は「検索ノイズと検索漏れ」について説明します。
前回Solrでは転置インデックスを作成して全文検索を行うと紹介しましたが、その際に気をつけることとして検索ノイズと検索漏れがあります。
例えば「東京都」という単語には「京都」という単語が含まれています。「京都」で検索した場合に「東京都」と書いてある文書も検索結果に含まれてしまうのが検索ノイズです。 これは前回紹介した転置インデックスの作成方法の内、N-gramで起こりやすい現象になります。形態素解析の場合は辞書に載っている単語で検出するので「東京都」が辞書に載っていれば「京都」で検索した場合に「東京都」が結果に出ないようにすることが出来ます。
検索漏れは検索ノイズと逆で、例えば「小学校」「中学校」という単語が文章内に含まれている場合に、「学校」で検索したときに検索結果に含まれない場合が発生します。 検索漏れは形態素解析の場合に起こりやすい現象となっています。N-gramでは基本的に検索漏れは起こりません。
全文検索では単語の検出方法によって、検索ノイズと検索漏れが起こります。
その他にも以下のような特徴があります。
用途に応じて使い分けましょう。
We are proud to announce that atWare is now a Typesafe System Integrator.
"We're very excited about this opportunity. Typesafe's support of reactive application development is closely aligned with atWare's focus of providing scalable solutions for customers. We're looking forward to working closely together." said Koji Kitano, VP of atWare.
By partnering with Typesafe, atWare can leverage the powerful combination of Scala, Akka middleware, Apache Spark, and developer tools via the open source Typesafe Stack, as well as commercial support, maintenance, and operations tools via the Typesafe Subscription service. As a Typesafe partner, atWare will provide consulting services to accelerate the commercial adoption of Scala, Akka, and Apache Spark.
KEY チームのアライです。技術系以外のネタです。
弊社では数々のブカツドウを行っています。
ブログでも紹介しています「はんだ部」を筆頭に、「自転車部」、「ラーメン部」などなど…
その中の一つにアライ一人で活動しているフットゴルフ部があります。
What is FOOTGOLF ???
サッカー(フットボール)とゴルフを融合した新しいスポーツで、
一言で言うと「サッカーボールを蹴って、ゴルフをする」です。
※日本フットゴルフ協会抜粋
2014年2月に日本フットゴルフ協会(http://www.jfga.jp/)が発足しましたが、
2009年にはオランダでルール化され、2012年にはハンガリーで第一回ワールドカップが開催。
現在欧米を中心に30カ国以上でプレーされています。特にイギリス、オランダ、アルゼンチン、ハンガリーが盛んなようです。
世界ではジワジワ来ているフットゴルフですが、日本ではまだプレーできるゴルフ場が少なく、
現在常設コースを持っているゴルフ場は全国で栃木宇都宮、兵庫三田、静岡御殿場の3つのみ。
このような環境の中、協会の尽力により1day大会を開催させてくれるゴルフ場は少しずつ増え、
これまで協会主催大会のジャパンオープンが各地で12回実施されています。
2015年1月に日本フットゴルフ協会が国際フットゴルフ連盟(FIFG)に正式加盟したこともあり、
先月6月5~7日にオランダで開催された国際大会「THE CAPITAL CUP(キャピタルカップ)」に
日本フットゴルフ協会が選考した日本代表を派遣することになりました。
4つのジャパンオープン兼代表選考大会における獲得ポイント上位6名が初代日本代表候補となり、
な、なんと私アライが総合2位で初代日本代表に選出され、日本代表として国際大会に参加してきました!!
選出された記事はコチラ。
候補として選出されたことが「スッキリ!」で少し放送されたこともあり、
各方面から応援が届き、非常に嬉しく思うと同時に、日本代表としての重みを感じました。
会社から餞別もいただき、またお休みも快く承諾して貰い、気持ち良くオランダに向かいました。



初めてヨーロッパ。
「THE CAPITAL CUP(http://www.footgolfcapitalcup.com/)」はヨーロッパツアーの1大会で、3日間でチャンピオンを競います。
ヨーロッパツアーの中で最も規模大きく、参加者も多い大会です。今回は世界13カ国110人が参加しました。
大会会場となったゴルフ場は非常に大きく、隣のホールではラフな格好でゴルフを楽しむ地元の方々が見られました。
【初日】
イギリス人、オランダ人、ハンガリー人、イタリア人、そして日本人のパーティーでスタート。
緊張の中、初の国際大会で初のティーキック。
普段通りのキックができ、初ホールで初バーディー!
しかしその後は続かず、ボギー、ダブルボギーなどもあり、18ホールで「+1」で初日を終えました。




【二日目】
この日のパーティーは初日とは異なるイギリス人、オランダ2人、ハンガリー人、そして私。
前日の経験を活かしてスコアを伸ばしたいところでしたが、18ホールで「0」。トータル「+1」。
しかも池ポチャのオマケ付きです…




【最終日】
全選手が1番ホールからのスタート。
オランダ人、ハンガリー人、フランス人、アイルランド人、そして私。
最後は楽しみつつ、しかし結果にこだわって戦うも、18ホールで「+2」。
3日間のトータルは「+3」で、最終順位は60位タイでした。



滞在期間中は天気に恵まれ、一緒に回った選手達もコースも素晴らしく、ヨーロッパでのトップ大会と実感しました。
良い結果は出せませんでしたが、国際大会のコース、雰囲気などを感じ、
また程良い緊張感の中でプレー出来たことは貴重な経験となりました。
「THE CAPITAL CUP 2015」の様子はコチラ↓
1:22にアライが出ています!
2016年1月7~10日にアルゼンチンで開催される「FIFG アルゼンチン ワールドカップ2016」の日本代表選考会が
今週日曜(7/19)の「第13回フットゴルフジャパンオープン」を皮切りにスタートします。
ワールドカップはサッカーに携わって来た者としては、まさに夢の舞台。
サッカーと関係性のある競技なので、是が非でも参加したいです!
11月には良い報告が出来るように頑張ります。
尚、フットゴルフにご興味のある方は、是非ご一報下さい!
フットゴルフ部部長アライ:araco@atware.co.jp
皆さん、こんにちは。KEYチームの矢納です。少し間が空いてしまいました。
過去記事の目次はこちらに移動しました。
今回RaspberryPiにサーバをたてるのにFlaskを使ってみたので、使い方を紹介しようかなと思います。 RaspberryPiにサーバを立てるということで軽量なWEBサーバは何だろうと調べたら、Flaskがヒットしました。
Flask(フラスク)は、プログラミング言語Python用の、軽量なウェブアプリケーションフレームワークである
wikipediaにしっかりと書いてありました(^o^)
では、今回試した事の紹介に入りたいと思います。全てRaspberryPi上実行しています。
$ sudo apt-get install python-pip
$ sudo pip install Flask$ mkdir flask && cd flask
$ vi index.py$ python index.pyWEBサーバが起動したので、http://<IPアドレス>:5000/にアクセス。Hello Worldと画面に表示されます。
$ openssl genrsa 2048 > server.key
$ openssl req -new -key server.key > server.csr
$ openssl x509 -days 3650 -req -signkey server.key < server.csr > server.crt
$ rm -f server.csr作成した鍵たちは任意のところに保存しておいてください。
起動時の設定に証明書を設定
server.crt と server.key は先ほど保存したパスを指定して下さい。
これで https://<IPアドレス>:5000/ にアクセスすると無事にsslでの通信が完了です。
こちらのサイトを参考にやってみました。
こちらのサイトに説明になってしまうので、簡単に説明します。
このブログで書いたコードはGitHubにあげてありますので、参考にしてください。 https://github.com/Burning-Chai/Flask
Email: yanou at atware.co.jp
皆さんMackerelをご存知ですか?
Mackerel とは はてな社が提供しているサーバー監視のサービスで、 サーバーにエージェントと言われるモジュールを設置するだけで、サーバーの状況がブラウザからグラフィカルに確認できるサービスです。
また、監視ルールを設定しておくことにより、サーバーが特定の状態(CPU使用率90%以上など)になった場合アラートを通知したり 無料プランでも一部制限はありますが、サーバー5台まで監視可能など、お手軽、便利、太っ腹なサービスです。
今回は、そんな本来はサーバー監視のサービスであるMackerelを本来の用途以外に使ってみようと思います。
だんだん気候も夏めいて来た今日このごろ、やはり気になるのはオフィスの環境。 健康を害するような環境で仕事をしないためにも、暑さで仕事の効率が落ちないためにも職場環境には気を使いたいところです。
というわけで、今回は職場(でなくてもいいですが)の温度と湿度を計測したいと思います。
では、実際に監視システムを構築していきたいと思います。
この実体配線図のようにAM2320をRaspberry Pi と接続します。 AM2320は型番のシルク印刷を表に見た場合、 左から * VDD <-> Pin #2 5V * SDA <-> Pin #3 SDA * GND <-> Pin #20 等 GND * SCL <-> Pin #5 SCL と接続します。

今回使用する AM2320 という温湿度計モジュールは I2C インターフェース経由でデータを取得します。 RaspberryPIは初期状態ではI2Cが有効になっていないため、 こちらのページ を参考にし、I2Cを有効にします。
こちらのコード をベースにし、出力をMackerelに対応させたコードがこちらです。
これをRaspberryPI上でコンパイルし、パスの通った場所に配置します。
$ curl -LO https://gist.githubusercontent.com/yenjoji/40d135519a0741d3718b/raw/5c7835651a539f16f3446108e15aa482f6c2111f/am2321.c $ gcc -lm -o am2321 am2321.c $ chmod a+x am2321 mv am2321 /usr/local/bin `
Mackerelのヘルプにそって、オーガニゼーションを作成します。
パッケージをダウンロードし、インストールします。
$ curl -LO http://file.mackerel.io/agent/deb/mackerel-agent_latest.all.deb $ sudo dpkg -i mackerel-agent_latest.all.deb
通常ならば、パッケージをインストールすれば完了ですが、 RasperryPiはもともとMackerelが想定しているCPUとアーキテクチャが違うためかそのままではうまく起動しません。 そのため、RaspberryPiのCPUにあったアーキテクチャのMackerelの実行ファイルで上書きします。
$ curl -LO https://github.com/mackerelio/mackerel-agent/releases/download/v0.17.1/mackerel-agent_linux_arm.tar.gz tar xf mackerel-agent_linux_arm.tar.gz $ sudo mv /usr/local/bin/mackerel-agent /usr/local/bin/mackerel-agent.org sudo mv mackerel-agent_linux_arm/mackerel-agent /usr/local/bin/mackerel-agent
インストールが完了したので、設定をしていきます。
設定ファイルに apiKeyとカスタムメトリクスの設定を追加します。 /etc/mackerel-agent/mackerel-agent.conf に オーガニゼーションの画面に表示されているAPIKEYと 以下のカスタムメトリクスの設定を追加してください。
# Get room status [plugin.metrics.temperature] command = "/usr/local/bin/am2321 -m" `
以上で設定がひと通り完了しましたので、エージェントを起動します。
$ sudo /etc/init.d/mackerel-agent start
これで、先ほど作成したオーガニゼーションに自動的にホストが追加され、 mackerelのデフォルトの監視項目と、温湿度計のデータが記録されていくようになります。
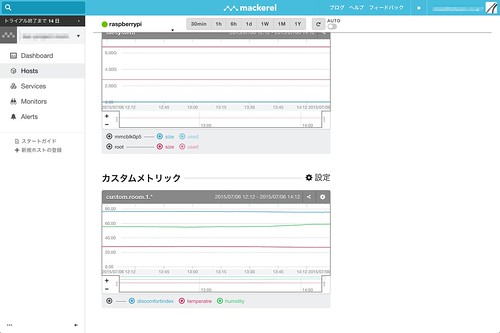
無事に温度と湿度の記録が始まりました。 しかしながらこれだけでは、職場が危機な状況になっても気づくことが出来ません。
ということで、職場の労働環境を監視する尺度として、不快指数を使って職場環境をモニタリングしたいと思います。
実は先程のMackerelカスタムメトリクス取得プログラムには、温度、湿度以外に不快指数も取得できるようにしてあります。 なので、手順通りに設定した場合は、すでにカスタムメトリクス上に不快指数が記録されていると思います。
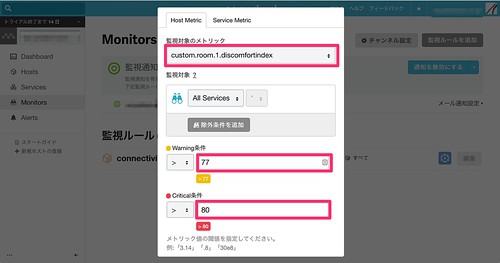
wikipediaによると、日本人は不快指数が77を超えた辺りから一部の方々が不快を覚え始め、80を超えるとみんなが不快感を感じるそうなので、 この値を超えた場合に通知が来るように設定したいと思います。
ポップアップしたウィンドウに監視条件を入力し作成ボタンをクリックします。 今回は不快指数(custom.room.1.discomfortindex)を選択し、77でWarning、80でCriticalとなるように設定します。
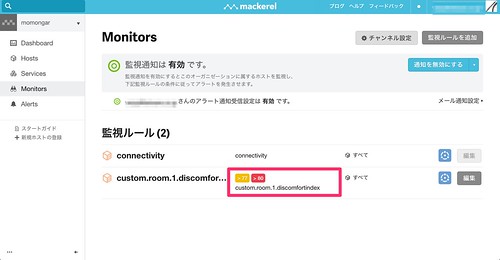
以前作成した、ズゴックXFDですが、 チームのみんながちゃんとテストが通ることを確認してからソースコードをPushするため、ほぼ活躍する機会がありません。 このままだと ただ職場にガンプラをおいている人になってしまう ので、 ズゴックの存在意義を上げるべく温度計を連携させたいと思います。
晴れてズゴックに温度計が付き、職場の状況をモニタリングすることが可能になりました。
これで、自分の居室の不快指数を計測し放題です。 計測したところで、特に快適になったりはしないのは残念ですが、 計測データを元に現場のリーダーに職場環境のカイゼンをお願いする材料くらいにはなるはずです。
ただ、残念ながら、温度計を付けてもズゴック見た目に変化がないので、 相変わらず傍から見るとガンダム好きな人にしか見えないという点は今後の課題とします。
みなさんもMackerelと様々なセンサーを組み合わせて遊んでみてはいかがでしょうか?
こんにちは、KEYチームの荒木です。先月来日していたPriyatamさんがタスクランナーでsassのコンパイルの遅さを指摘されていました。たしかにそうですね。では他の状況はどうかと思い、watchifyを使ったlivereload環境の速度と安定性について npmとgruntとgulpで比較してみることにしました。
live-serverで環境を構築、速度を考えてwatchifyで差分ビルド。
保存した0.5から1秒後にリロードされました。起動も早いですし安定した動きですね。
yeomanによくあるconnect-livereloadで環境を構築。
かなり早いですね。押した瞬間にリロードされました。ですが、保存直後すぐに修正して保存した場合に限りリロードされても反映されませんでした。 すぐに修正することも少ないのでほとんど影響ない範囲ですね。
browser-syncを使ったlive環境
npmとかわりないですね。
gulp-live-serverをつかってもlive環境をつくれますのでやってみました。
QuickTimeで録画するとうまく動かず録画できませんでしたが、こちらもnpmと変わりないですね。
transformするコード量は少ないですが、Gruntが少し早いていどでそんなに大差はなかったですね。 なにを採用しても良い環境は作れると感じました。
チョット書く程度でしたらnpmで。 タスクをキレイに整理して書きたいのならgulpでしょう!
株式会社アットウェアは、今年の7月に米国Typesafe社とのコンサルティングパートナーを締結したことを機にScala, Sparkなどを活用し、Reactiveアーキテクチャを使ったシステム・プロダクト開発を推進していくため、新たにScala, Akka, Sparkエンジニアの採用強化を行っております。Reactiveアーキテクチャは、本来、固有のメーカーやフレームワークに依存するものではなく、耐障害性や柔軟性の高いシステムを構築していく考え方を指しています。それらの考え方を学んだ上で、Scala, Akkaを利用したシステム開発をさらに学んでいくことは非常に重要なことです。
そこで株式会社アットウェアでは、Scala, Sparkなどの技術を学べるインターンシップを実施しております。Twitter社やNETFLIXなど世界のトップリーディングが注目・採用しているアーキテクチャ・技術を無料で学べるチャンスです。興味が有る方は是非私達にコンタクトしてください。
期間:3ヶ月程度〜
*現職エンジニアについては、土日などを利用し、期間を延長して調整する場合あり
*個人のスキルにより期間を調整する場合あり
内容:
・講義(集合、オンライン教材)、演習、アプリ制作、プロジェクト
実施形態:オフライン + オンラインのミックス
・オフライン(講義、メンターへの質疑、プロジェクトへの参加)
・オンライン(オンライン教材、演習、アプリ制作)*オフラインでの実施も可能(アットウェアオフィスにて)
支給/貸与:
・自宅からオフィスまでの交通費、開発マシン、クラウド環境(AWSなど)
インターンで習得できること:
・関数型言語Scalaを使って、Web・サーバアプリケーションの作成
・Apache Sparkを使い、ストリーミング処理、ビッグデータ解析、繰り返しの機械学習などを行う基礎、およびデータサイエンスなどそれら応用への適用
応募方法:
以下の応募フォームにて御連絡ください。担当のものから必要書類や面接スケジュールなど御連絡します。
不明点がある場合も以下フォームから問い合わせください。
応募条件:
学生、ITエンジニア
プログラミング経験が1年以上あること
選考:
応募書類および面接にて選考
2015年7月7日、株式会社アットウェア(代表取締役 牧野隆志)は、日本のシステム開発分野において今後の新システムで求められているReactive System(以降リアクティブシステム)のシステムインテグレーションおよびコンサルティング事業を積極的に進めていくため、米国Typesafe社とコンサルティングパートナー契約を締結しました。
今日の求められているシステムに対する要件は高く、システムの利用者はミリ秒の応答時間と 100% の稼働率を期待し、データはペタバイト単位のものを分析しリアルタイムにユーザやアナリストにフィードバックするなどです。今実際に利用されているシステムアーキテクチャで、それらのユーザの要求をすべて満たすことは容易なことではありません。
リアクティブ宣言で宣言されているように、私たちアットウェアでは、Reactive System アーキテクチャがそれらの厳しい要件を満たすためのひとつの解とし、即応性、耐障害性、弾力性、メッセージ駆動を備えたシステム開発を進めていきます。より柔軟で、疎結合で、スケーラビリティがあるシステム開発をユーザ企業とアジャイル開発を通して推進していくことで、ユーザ企業のビジョンの実現を加速させるとともに、私たちのミッション"システムで人々をしあわせに"の実現を目指していきます。
Typesafe社は、JVM上で動作するScala言語の生みの親Martin OderskyがCo-founderとして創設したオープンソースソフトウェアをベースとしたビジネスをしているグローバル企業です。Play framework, Akka, Apache Sparkなど、Scala/Java等から利用できる、今日において先進的で有益なオープンソースソフトウェアにたいしてコントリビュートしているエンジニアが多く所属し、それらのコンサルティング、トレーニング、または開発・プロダクション環境においてのサポートサブスクリプションを提供しています。
Typesafeが進めているReactive SystemアーキテクチャのEcoSystemとして、それらScala, Play, Akka, Sparkなどがあり、株式会社アットウェアはそれらのEcoSystemに通じ、それらの技術を含むシステム構築、コンサルティングを日本国内で実施していきます。 具体的には、スループット問題などパフォーマンスに関わる事やスケールアウトの困難な問題、およびスケールアウトに伴う費用肥大化、またHadoopなどの大規模データの並列分散処理の効率化についてReactive Systemにより改善が見込まれます。また既存システムへの適応だけではなく、新規開発として、小規模システム〜大規模システムの初期構築についても威力を発揮し、弾力性(Elastic)を兼ね揃えたシステムを構築するのも可能となります。
株式会社アットウェアでは、今回のScala, Akka, Apache Sparkなどの先進技術、言語においてのシステム開発のコンサルティング、およびシステム開発(受託開発)を日本市場において実施などの新たな取組みと合わせて、グローバル開発の展開も視野にいれており、DevOps開発体制の強化も計画しております。
今後の株式会社アットウェア、Typesafe社のアクションにご期待ください。
I get asked periodically at work about getting started with Scala programming. This is a published answer to that question.
What is Activator?
Activator is SBT + a UI + a tool for downloading and installing templates that include tutorials. You don’t need anything else. Follow the link above to install it and get started.
What is SBT?
SBT is a build tool- it compiles your code and handles your dependencies. It’s just like Maven or Gradle, and has the most comprehensive support for Scala.
It’s easy to get started with SBT. There is substantial documentation available, including a book co-authored by one of the SBT committers, Josh Suereth.
Something to keep in mind as you’re getting started. There are, to my knowledge, three different syntaxes for writing build scripts with SBT. You’re liable to come across all three. The three are:
1- Straight up Scala When you see Build.scala, it’s straight up Scala code importing SBT. It’s fine, and it works, but it is not the latest form of SBT. I personally avoided looking at these examples, as I found them a little difficult to read.
2- build.sbt, with a space between each line This is a new/old style of SBT syntax. At one point in SBT evolution, the space between each line was used to delimit a line command. This was for SBT before 0.13.7. If you see this, it’s important to know that you are not looking at the latest SBT syntax.
3- build.sbt, without spaces between each line This is the latest version of SBT. 0.13.7 and later.
It’s quite common to scour github looking for examples of what you want to do. Keep these three syntaxes in mind as you do so.
There are some alternatives to using Activator.
giter8 has some interesting project templates you can install. Among other templates, there is a template for a Scala-based Android app.
conscript augments giter8, but I have not used this.
First, install Activator and it’s dependency, the JDK.
Then find a project to download and run. Check out the templates here, and find one you like. I would recommend the amazing, interesting Spray Spark React template, because it’s really well done and has fascinating tutorial (Disclaimer, I am the author).
The templates all have their own page explaining how to get started. But for completeness, just do this:
$> activator new amazing spray-spark-react
This will spit out some instructions for you
$> cd amazing
$> activator ui
This will launch a browser and the activator ui. This will allow you to browse and edit the code, as well as view the tutorial.
It’s always nice to have a fully functioning project to get started with a new development platform. Scala has a reputation for being a little bit difficult to learn. I think this is largely unwarranted, and there are some really good tools for getting started quickly. Go forth!
ホームページがリニューアルされてから、Shibboleth関連についての初投稿になります。
Shibbolethとは、米Internet2が開発したオープンソースのシングルサインオンを提供するするソフトウェアです。
日本では、特に学術認証基盤を実現する技術として採用されています。有名なのは、GakuNinですね。
GakuNinは、全国の大学等とNIIが連携して構築する学術認証フェデレーションであり、 公開されている情報では、IdPは、165の組織が参加しており、SPは、64サービスにものぼります。
構築のお手伝いをしてきた者の感覚になりますが、近年、GakuNinの参加機関が急激に増加しており、学術機関としては、Shibboleth対応して、GakuNinに参加するという流れができつつあるのではと感じてます。
弊社は、そのような ShibbolethのSPやIdPの構築を行っております。 簡単ですが、実績の紹介になります。
ここまでは、以前のホームページの中でもふれていたことですが、新たに下記のようなこともやっております。
このような実績と数多くのオープンソースソフトウェアの利用およびカスタマイズの経験を生かし、
今後も、大学やサービスプロバイダなどのお客様がShibbolethを導入して認証基盤を構築される際の支援をいたしてまいります。
Apache Spark is a great software project; a clustered computing environment that is well designed and easy to use. The attention it has been generating the last few years is well deserved.
Using Spark and SQL together has appeal for developers not accustomed to map, flatmap, and other functional programming paradigms. And allows developers to use SQL, a query language most are already familiar with.
Spark SQL can also act as a distributed query engine using JDBC. This is a useful feature if you plan to use Spark and SQL together, but the documentation falls a little short in places. This post is a first attempt to rectify that issue. It is a step by step guide to a fundamental method of connecting an SQL client to a standalone Spark cluster.
The first step is to download and set up Spark. For the purposes of this post, I will be installing Spark on a Macbook. It should be the same steps in general on any operating system.
At the time of this writing I am downloading a Prebuilt Spark for Hadoop 2.6 and later.
Download this prebuilt instance of Spark. Also download SquirrelSQL, the sql client this tutorial will configure to connect to Spark.
Next we need to do a little configuring.
I added the following environment variables to my .bashrc:
# Spark local environment variables export SPARK_HOME=CHANGEME!!! export SPARK_MASTER_IP=127.0.0.1 export SPARK_MASTER_PORT=7077 export SPARK_MASTER_WEBUI_PORT=9080 export SPARK_LOCAL_DIRS=$SPARK_HOME/../work export SPARK_WORKER_CORES=1 export SPARK_WORKER_MEMORY=1G export SPARK_WORKER_INSTANCES=2 export SPARK_DAEMON_MEMORY=384m alias SPARK_ALL=$SPARK_HOME/sbin/start-all.sh
You will need to change SPARK_HOME to the location where you unpacked the download. I configured the port that spark will use to commute, as well as the port for the webui. I configured it to use 1 core, two worker instances, and set some fairly strict limitations on memory.
I also added an alias to start all of them at once.
It is important to note that spark uses ssh to communicate with itself. This is a secure method of communication, but it is not common for a distributed system to talk to itself on a single machine. Therefore, you will probably need to do make some local changes to allow this on your machine. OSX has a Remote Login setting that allows this. Linux has several options. I don't recall what the Windows equivalent is. But to proceed beyond this first step, you will need to allow the workers to communicate via ssh.
Once you have your environment variables set, and they can communicate via ssh, we also need to add hive configuration. In order to connect with an SQL client, we're going to need to run a small server to act as a JDBC->Spark bridge. This server corresponds to the HiveServer2 (this is the Spark documentation wording. I really don't know what they mean by "corresponds to". I assume the Thrift JDBC/ODBC server is in fact HiveServer2).
In order to run the Thrift Server/HiveServer2 we will need to configure a location for the server to write metadata to disk.
Add the following file to $SPARK_HOME/conf/hive-site.xml
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:derby:;databaseName=<my_full_path>/metastore_db;create=true</my_full_path></value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>org.apache.derby.jdbc.EmbeddedDriver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>hive.metastore.warehouse.dir</name> <value><my_full_path>/hive-warehouse</my_full_path></value> <description>Where to store metastore data</description> </property> </configuration>
Now, with the configuration out of the way, you should be able to run spark all. Via the alias I described above,
# > SPARK_ALL
On my Macbook, I am prompted for my password twice, once for each work I configured. You can configure ssh with keys to avoid this, but I'm not going to discuss that in this post.
To test that your Spark instance is running correctly, in a browser go to http://127.0.0.1:9080
Note that $SPARK_HOME/sbin/stop-all.sh will stop everything.
Spark provides a number of convenient ways to add data. Presumably one might do that via database, but for this demonstration we're going to do use the method described in the Spark documentation.
We will use the data provided here
# > cd $SPARK_HOME
# > bin/spark-shell
scala> val dataFrame = sqlContext.jsonFile("path/to/json/data") scala> dataFrame.saveAsTable("tempdepth")
Storing this data as a table will write metadata (ie, not the data itself) to the hiveserver2 metastore that we configured in an earlier step. The data will now be available to other clients, such as the SQL client we're about to configure.
You can close the spark shell now, we're done with it.
So now we have a running Spark instance, we have added some data, and we have created an abstraction of a table. We're ready to set up our JDBC connection.
The following is reasonably well documented on the spark website, but for convenience:
# > $SPARK_HOME/sbin/start-thriftserver.sh --master spark://127.0.0.1:7077
You should see a bunch of logging output in your shell. Look for a line like:
"ThriftCLIService: ThriftBinaryCLIService listening on 0.0.0.0/0.0.0.0:10000"
Your thrift server is ready to go.
Next, we will test it via beeline.
# > $SPARK_HOME/bin/beeline beeline> !connect jdbc:hive2://localhost:10000
This will prompt you for your password and username, you can use your machine login name and a blank password.
The resulting output should say "Connected to: Spark Project Core".
Now you know you can connect to spark via JDBC!
If you haven't already done so, download SquirrelSQL.
First, you will need to add the JDBC driver. This is the Hive driver, and to get that you can either download hive, or use the two jars I have provided in my github repo. hive-cli and hive-jdbc are the required. As are some classes in the spark-assembly jar. Add those to the Extra Classpath and you should be able to select the HiveDriver as the image below describes.
Save this driver.
And finally we will create a connection alias. Give the alias a name, select the driver you just created, and the URL should look like the image below.
Once you have created the alias you can click the Test button to test your connection. Hopefully you are successful!
Once you connect, you should be able to find the table you created earlier, and query via SQL.
Sunset over the Golden Gate bridge
Last March, I attended ScalaDays in San Francisco. It was a fantastic experience!
I came away with a much better understanding of the Scala ecosystem, and was really impressed with the caliber of speakers at the event. I volunteered as a staff member, which is something I would recommend to others.
In fact, I should put in a plug for this- last year at OracleWorld I volunteered to teach kids to program with Devoxx4kids. I would highly, highly recommend it to anyone even remotely interested. It was an incredibly rewarding experience, and I got to meet awesome people.
This volunteer event was a bit different- I didn't get to hang out with kids interested in programming, for one, and I had to do manual labor. But I still got to meet awesome people, so it was worth it. If you're going to a conference, it's good to meet people. If you just go there, absorb the lectures, drink beer and hang out with your coworkers, I think you are missing out. So next time, volunteer, and you'll have a better time.
Ok, with that aside, here are some thoughts a month or so after the event.
Martin Odersky introduced Tasty files to me during the keynote at Scaladays. I had never heard of them before, and they are still somewhat of a mystery to me. I'm dying to work with them. It is such a cool idea, I just have not had the time yet to see what is available now and figure out how it will work.
The gist is that Tasty files will solve binary compatability issues going forward for Scala, and at the same time will also allow the compiler to convert Scala to both class files and Javascript. To paraphrase something I attribute to Odersky but can not longer seem to find on the internet, Scala is no longer be a single platform language. So I've got that going for me, which is nice.
If you are a developer and do not live under a rock then you have probably heard of Apache Spark. Reynold Xin gave a really nice recap of the effort required to take a vanilla Spark instance turn it into a Sort Benchmark winner.
What you may not know is that Spark was initially developed with Akka. I'm not sure if it still uses Akka or not.
I attended the Shapeless talk and came away feeling a bit shapeless about the whole thing, actually. But after reading a little bit about it, it's easy to see why the talk was so well attended. The generic programming library is definitely worth looking at further.
My one regret was not attending a ScalaJS talk, it was brought up repeatedly in the key note, and it's definitely worth looking at further. ScalaJS has support for use with ReactJS and Angular,
Here are the complete list of talks from the conference if you're interested in checking them out.
One last bit- I attended Advanced Akka Training after the conference. It was put on by BoldRadius. One of the instructors, Michael Nash, also spoke at the conference. The training was excellent.
みなさんこんにちは。アットウェアの不破です。
前回はMoodle全体の事を書きましたが、今回はMoodleのもっと奥深い事を書いていきます。
Moodleはプラグインを導入することで利用できる機能を拡張することが出来、ここがMoodleの醍醐味です。インストールすることが出来るプラグインにも種類がありますが、今回は「ブロック」について取り上げます。
画面左右に出てくる、これです。

ブロックはサイトトップ・コース画面・マイページに設置することが出来、ドラッグアンドドロップで左右であれば自由に配置できます。 ブロックを配置するときのコツは、「注意を引きつける」にあります。「〜さんが投稿しました!」や「締め切りが近い課題があります!」といった情報を表示させる場所として最適です。
サードパーティー製のブロックはmoodle.orgからもダウンロードすることが出来ます。 https://moodle.org/plugins/browse.php?list=category&id=2
ブロックは基本的に何個でも配置できるのですが、あまり多く配置してしまうとサイト全体が重たくなってしまうため、多くても10個程度にするのが最適です。また、ブロックが多いと学生の注意を引きつけにくくなります。
ちなみに私は"Misaka"という「コンシェルジュブロック」を開発しています。 https://github.com/yuesan/moodle-block_misaka

Moodleが持っているログデータを分析しその日のアドバイスを表示させるブロックで、状況に応じてキャラクターの表情も変わるようにしています。 学生さんのモチベーションをアップさせることを目的としており、「毎日Moodleにログインし、学習してもらえるようにサイトを明るくする!」を目指しています。 ちなみにMisakaは、今年のMoodle Mootで「ベスト・ムードル・イノベーション賞」佳作を頂いております。
ブロックはMoodleのプラグインにおいても比較的開発しやすい方で、下記URLにテンプレートが準備されています。 https://github.com/danielneis/moodle-block_newblock
次回は「mod」について紹介します。
みなさん、こんにちは。lunettesチームの的場です。 前回に引き続き、全文検索システム「Solr」を紹介していきます。
全文検索では検索を高速に行うため、あらかじめ転置インデックスというデータを作成しておく必要があります。
転置インデックスは専門書の最後の方に付く索引をイメージしてもらえばわかりやすく、どのような言葉がどの文書のどの位置に存在するかを記録したデータです。
作成された転置インデックスは特定の順序で並べられており、検索で指定された文字や文章が索引に存在するかを高速に調べ、存在する場合はどの文書内に検索したい文字や文章が含まれているか取得することが出来ます。
転置インデックスを作る際に一番問題となるのは単語の検出方法です。英語のような言語ではスペースで単語が区切られているため、単語の検出が容易ですが、日本語ではどこまでを一つの単語として扱うかは課題が多いです。
日本語における転置インデックスの作成方法としては形態素解析を用いる方法とN-gramを用いる場合があります。
形態素解析は辞書に登録してある単語に基づいて単語を検出する方法です。
例えば、「アットウェアは神奈川県横浜市西区みなとみらいに所在しています」という文章に形態素解析処理をすると以下のようになります。
形態素解析は辞書に載っている単語で区切りますので、この辞書にはアットウェアは登録されていないようですね。アットウェアが辞書登録されていれば、アットウェアのひとかたまりで名詞として検出されます。
形態素解析を使うことによりこの文書に含まれている単語は「アット」「ウェア」「神奈川県」「横浜市」「西区」「みなとみらい」「所在」などであることがわかり、それらを転置インデックスに登録することにより、その単語が含まれる文書を高速に探すことが出来るようになります。
n-gramは意味のある単語は意識せずに、文字数で文章を区切って単語を検出する方法です。 1文字で区切る場合はuni-gram、2文字で区切るbi-gramと呼びます。
bi-gramで「神奈川県」という単語を区切った場合は「神奈」「奈川」「川県」という単語が検出されます。
検索で指定された言葉もbi-gramで区切って検索するので「神奈川」で検索した場合は「神奈」と「奈川」が含まれる文書を探すことになります。
形態素解析のメリットとしては「n-gramに比べて転置インデックスのデータ量が小さい」点で、デメリットとしては「検索漏れがある」があります。
n-gramのメリットとしては「検索漏れがない」点で、デメリットは「転置インデックスのデータ量が大きい」「検索ノイズが多くなる」になります。
検索漏れと検索ノイズについては重要な内容ですので、次回詳しく説明します。
みなさん、こんにちは。KEYチームの矢納です。
過去記事の目次はこちらに移動しました。
プロジェクトでCentOS 5.8(32bit)を使うことがあり、vagrantのboxを探していたのですが、見つかりませんでした。
vagrantのboxは http://www.vagrantbox.es/ に置いてあります。
ですが、ここにはCentOS 5.6(32bit)、CentOS 5.8(64bit)しかありませんでした。今欲しいのはCentOS 5.8(32bit)だよ。
無いのなら作るしか無い精神で今回作ってみました!
今回はその手順を紹介して行きたいと思います。
ここのインストール方法は省略します。各々のサイトからダウンロードしてインストールしてください。
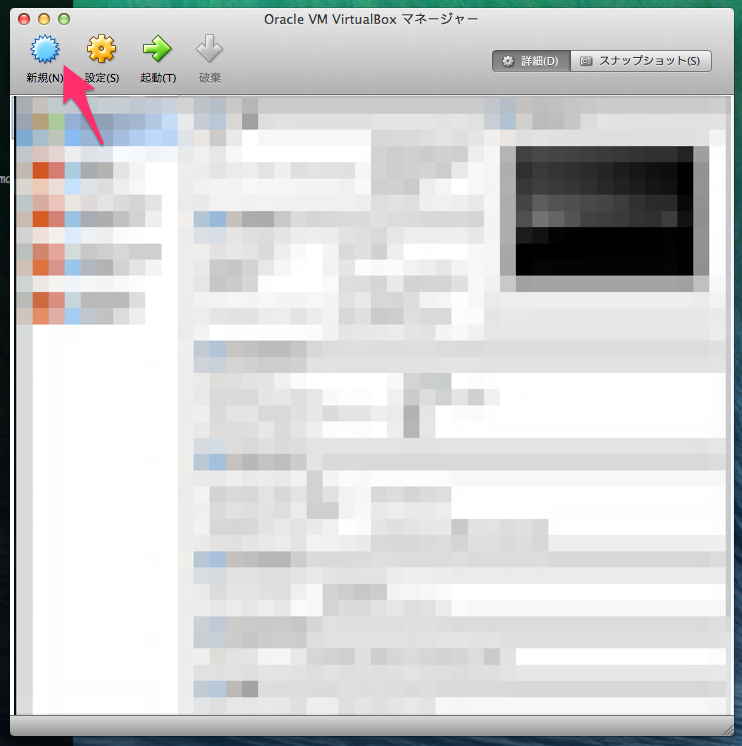
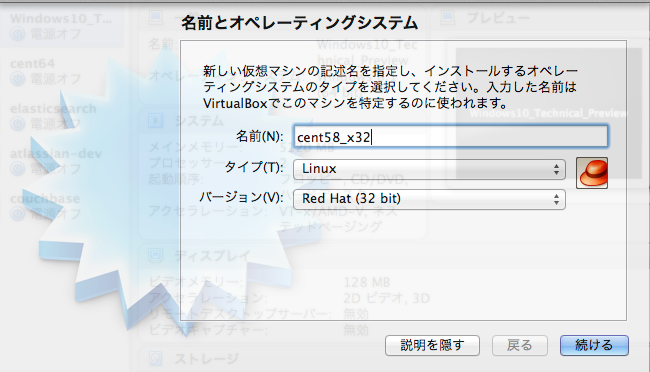
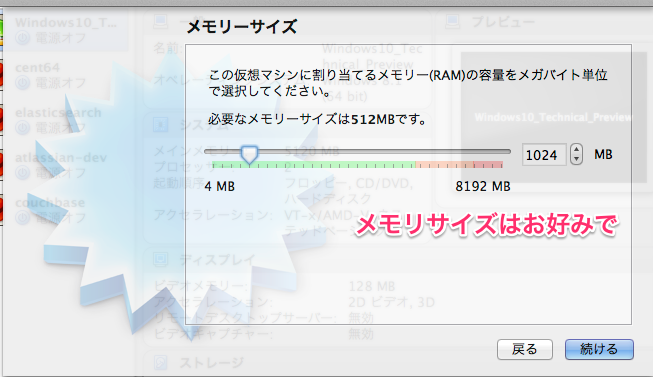
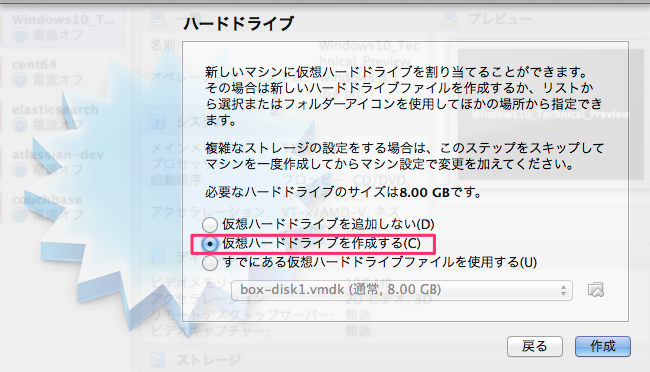
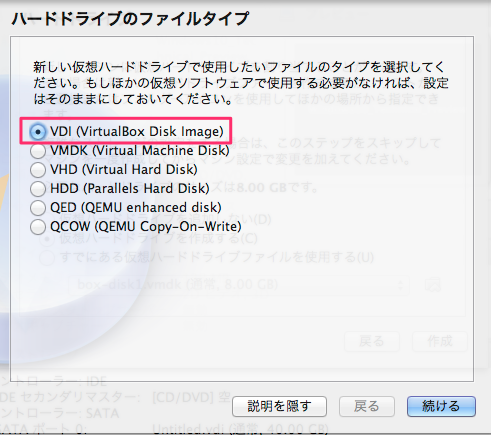
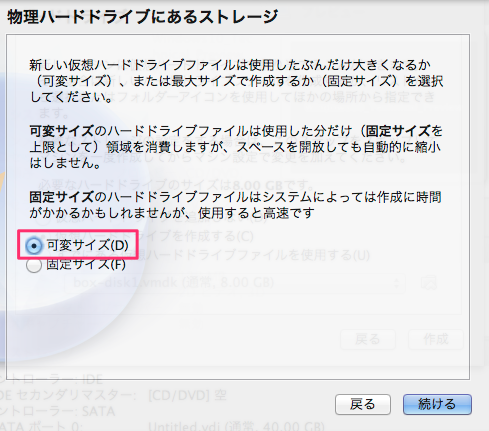
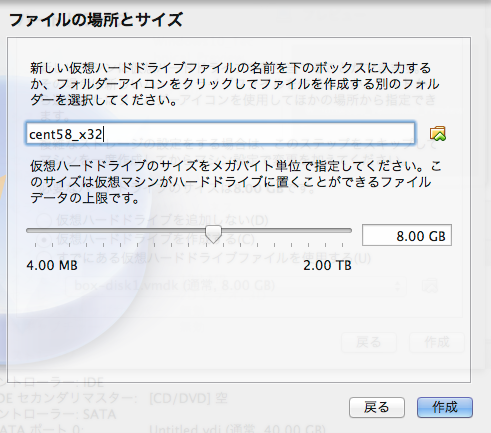
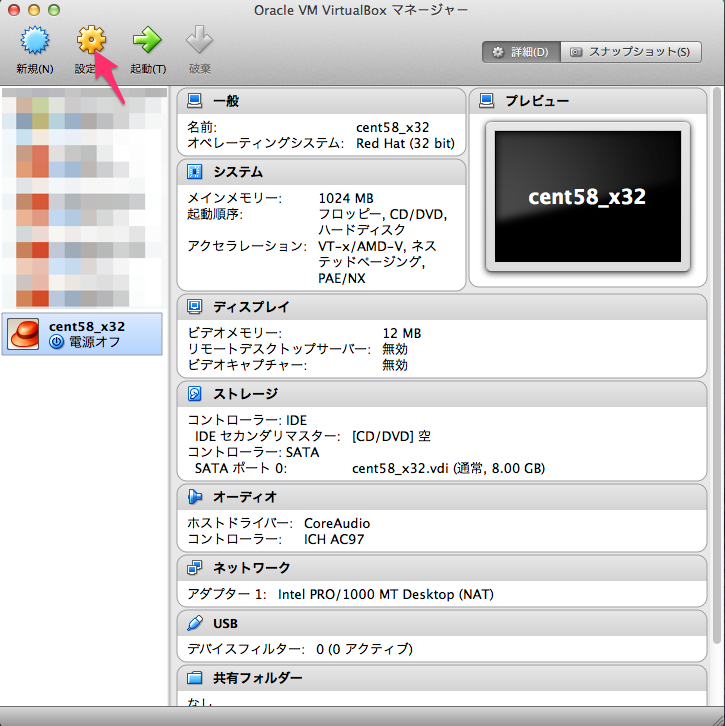
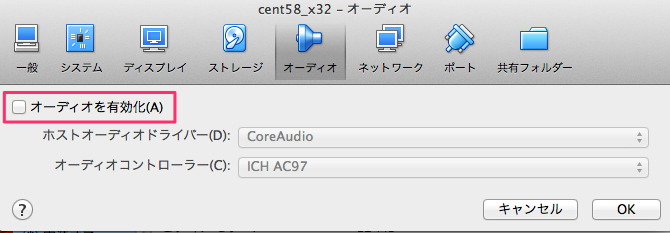
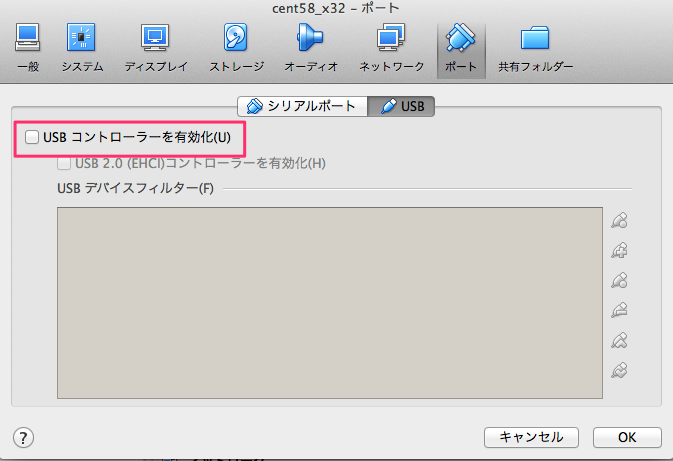
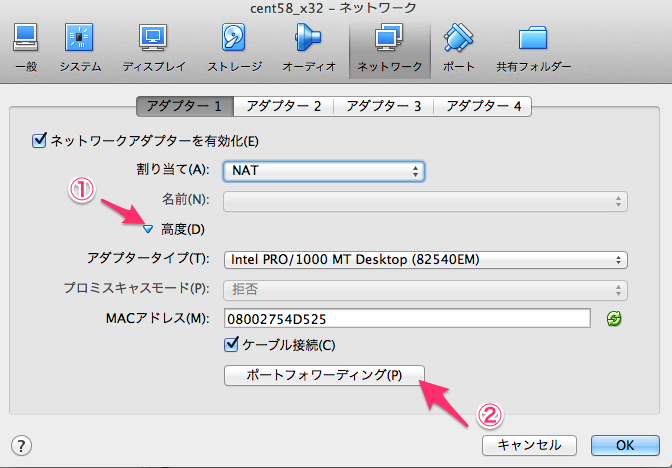
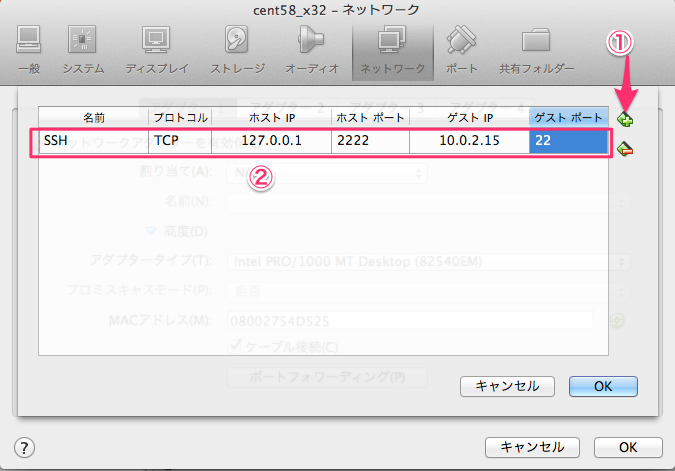
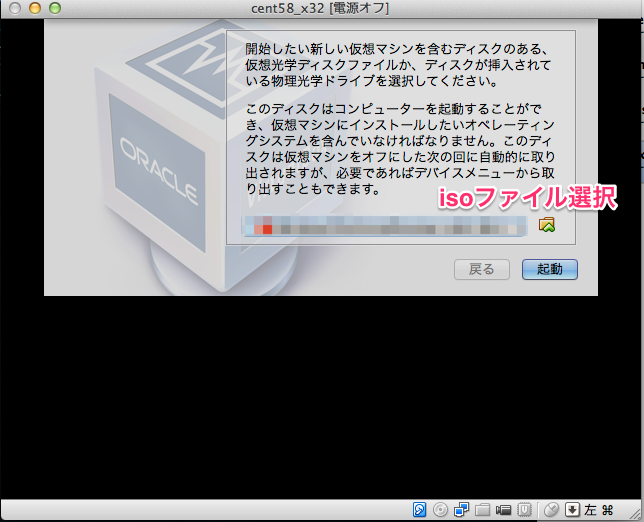
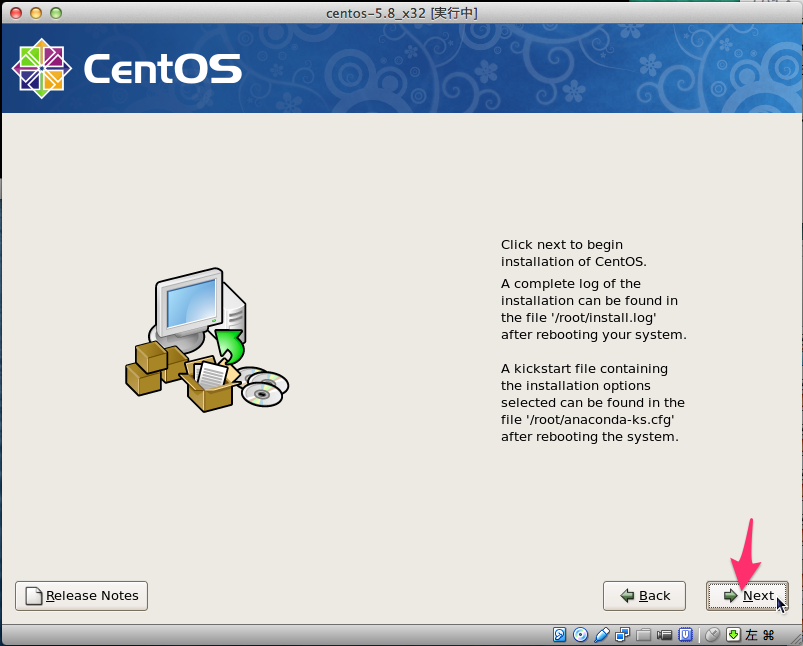
新規作成ボタンを押して下さい。ここでisoファイルの指定ができます。 ここでは CentOS-5.8-i386-netinstall.isoを使いました。
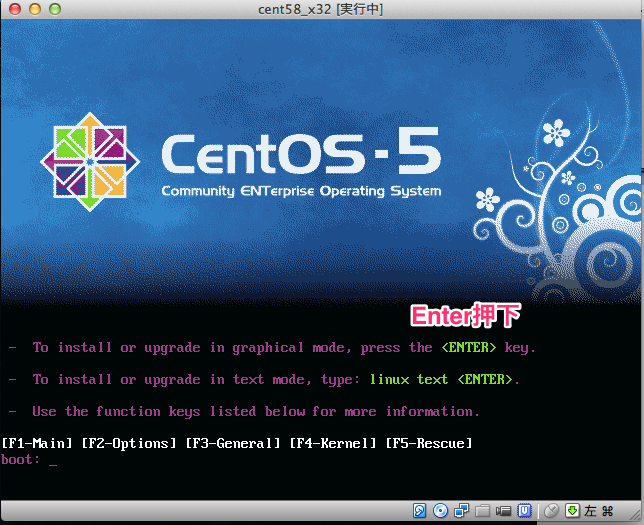
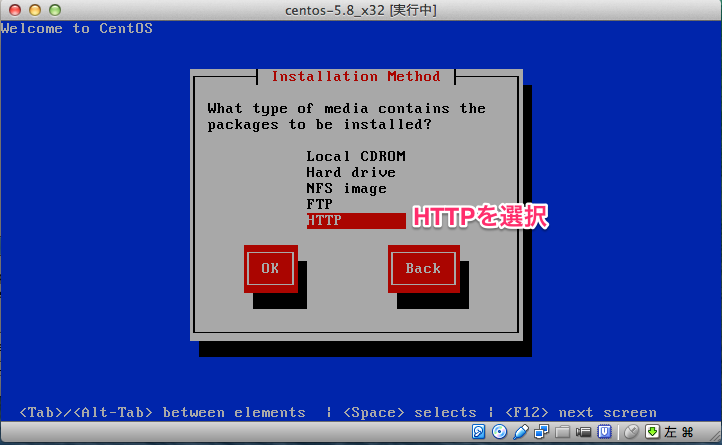
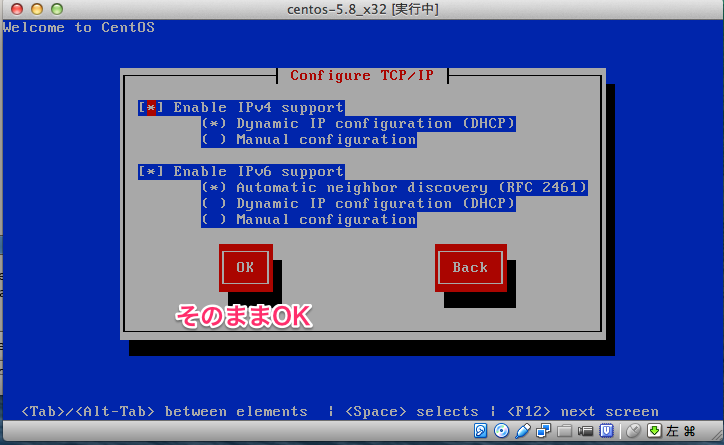
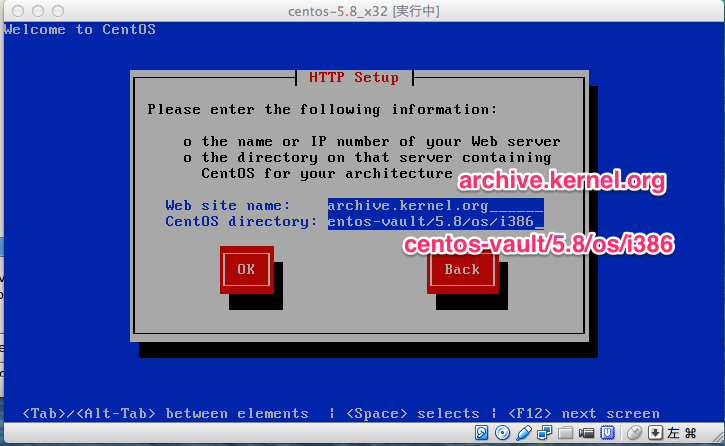


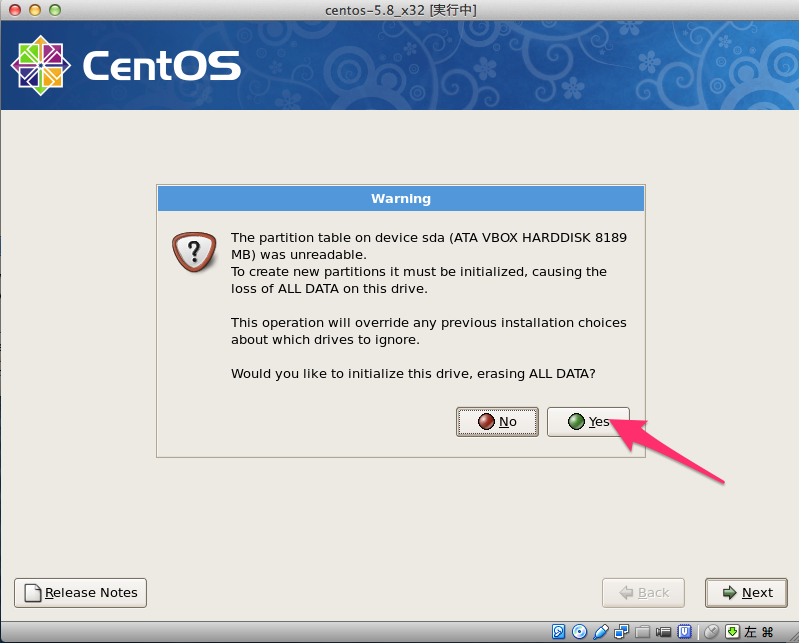
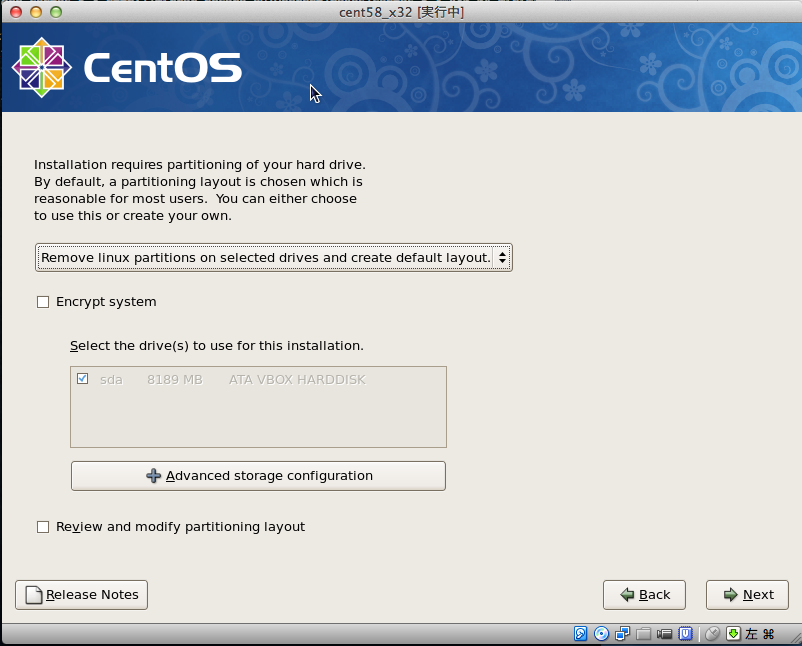
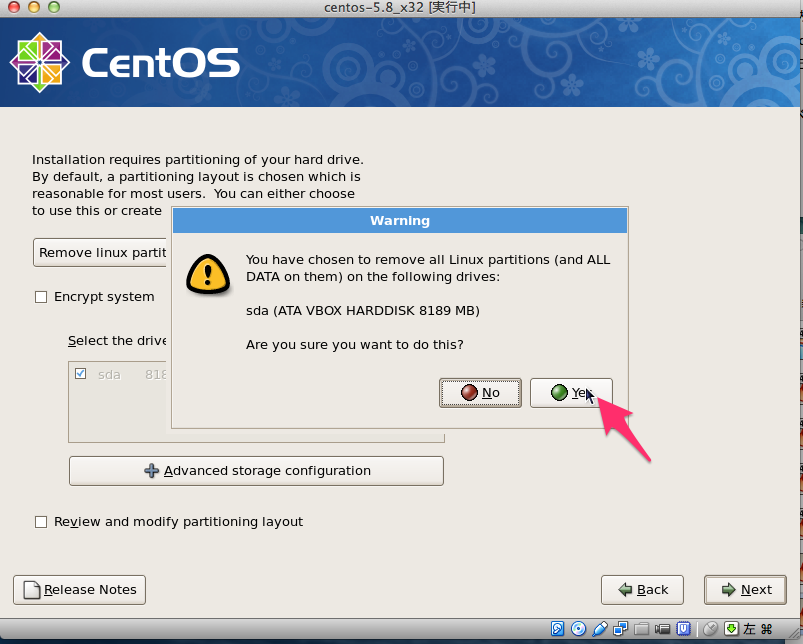
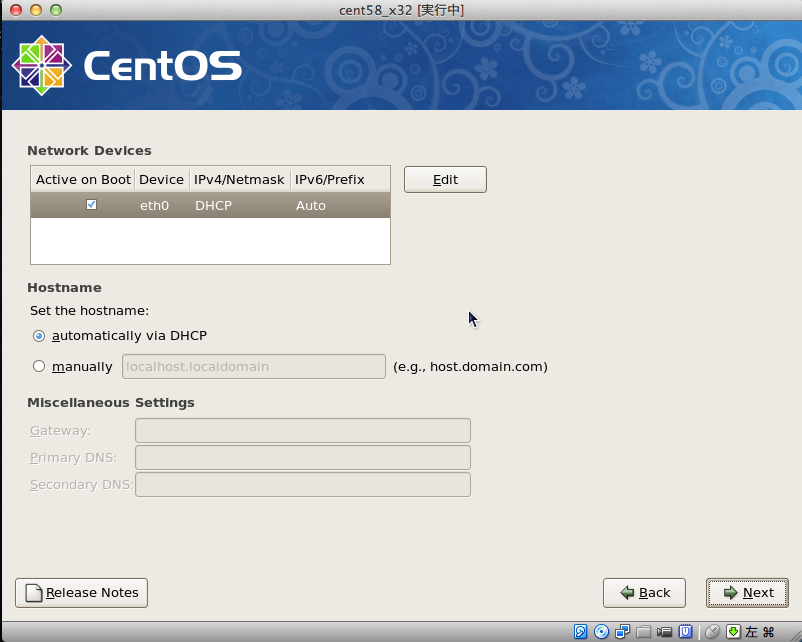
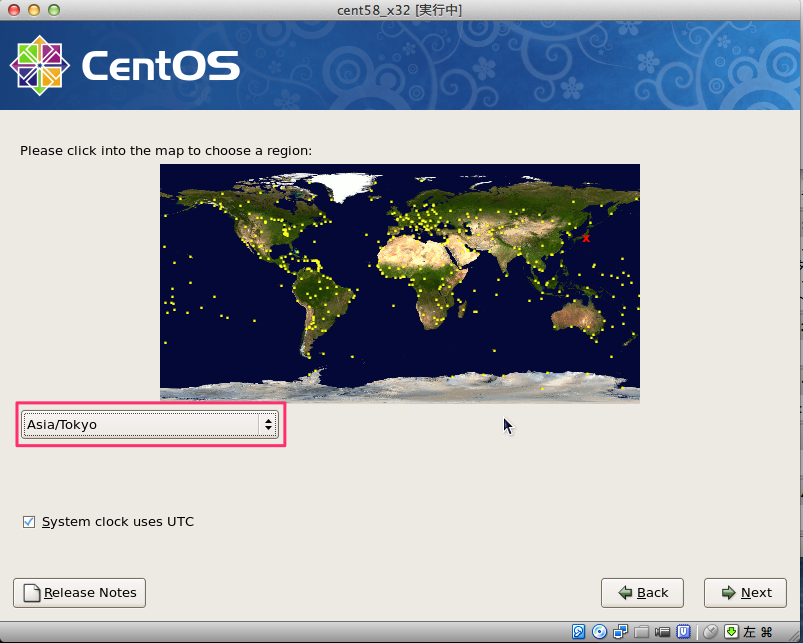
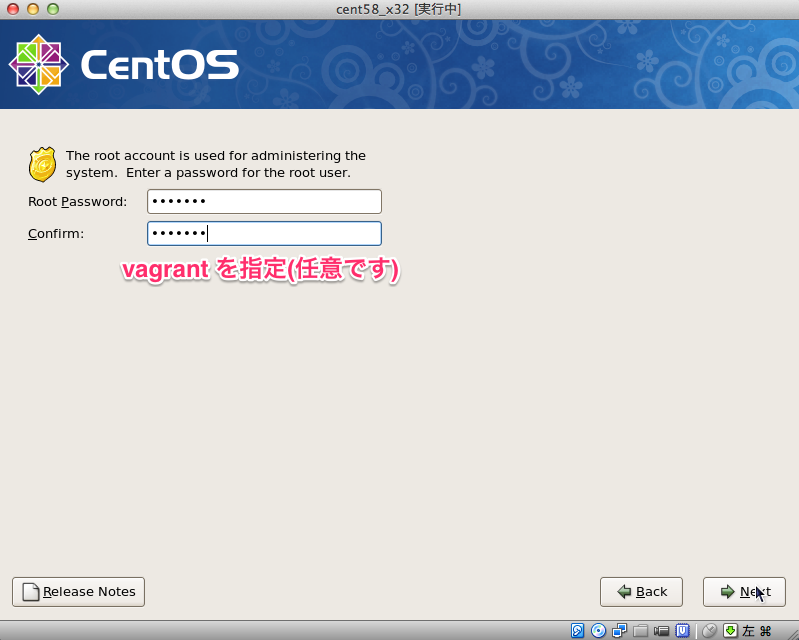
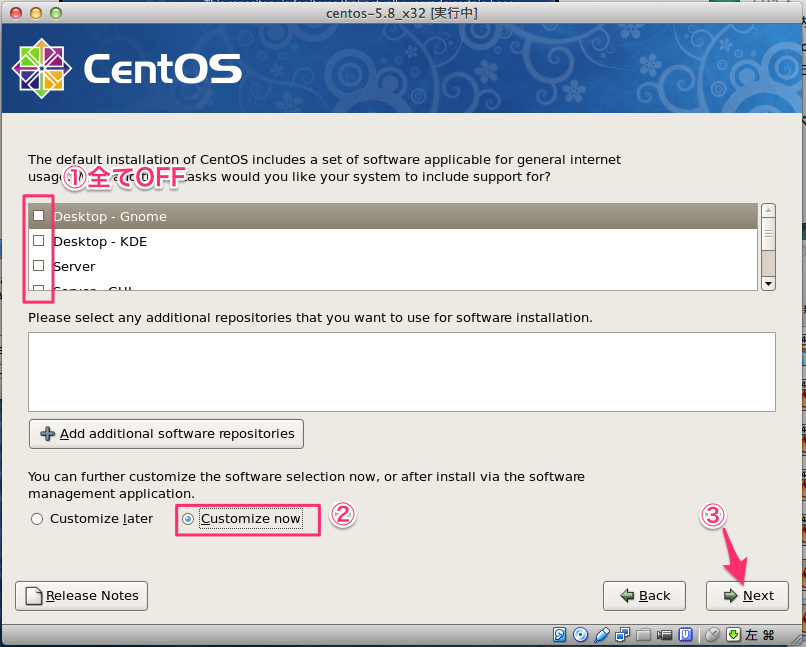
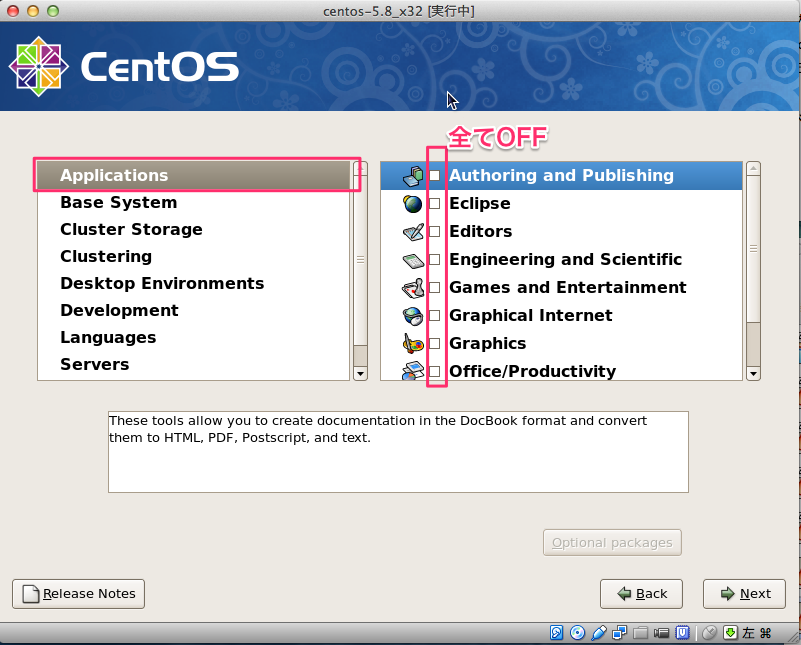
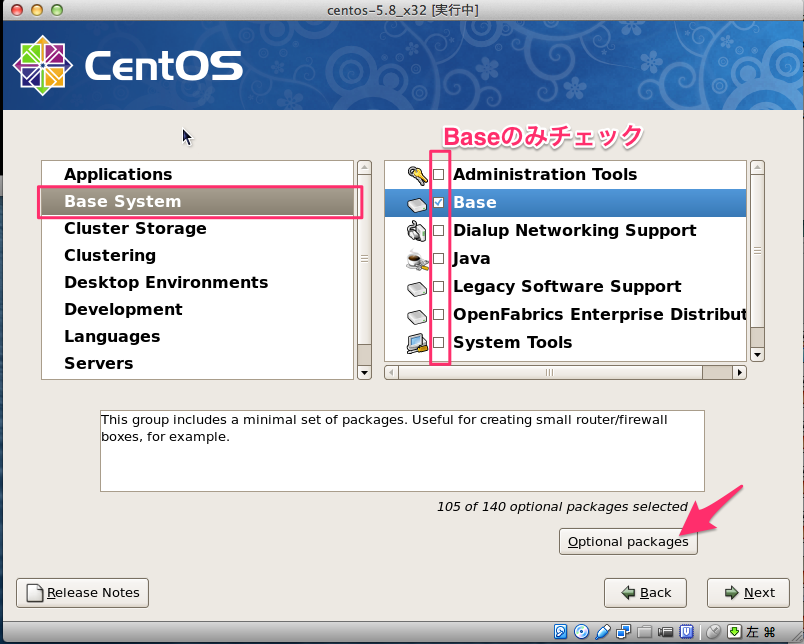
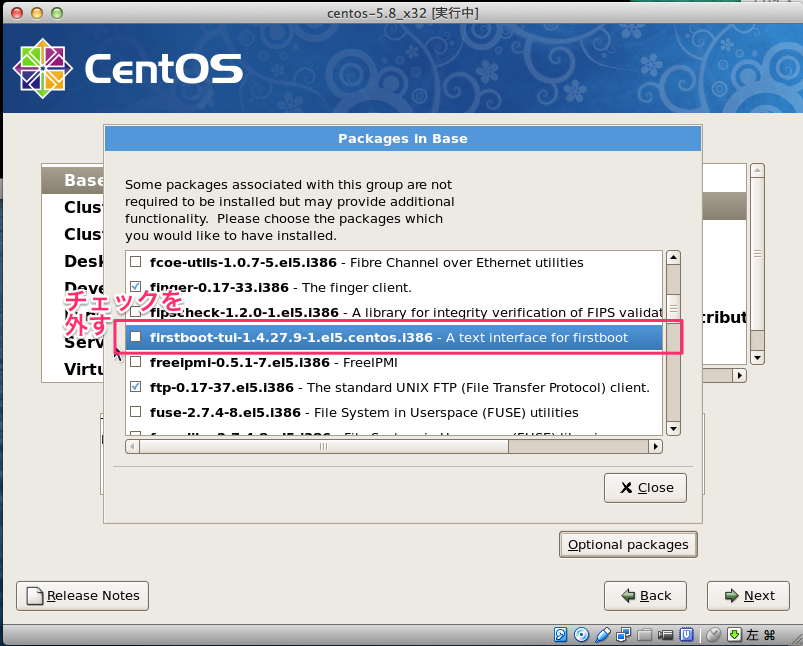
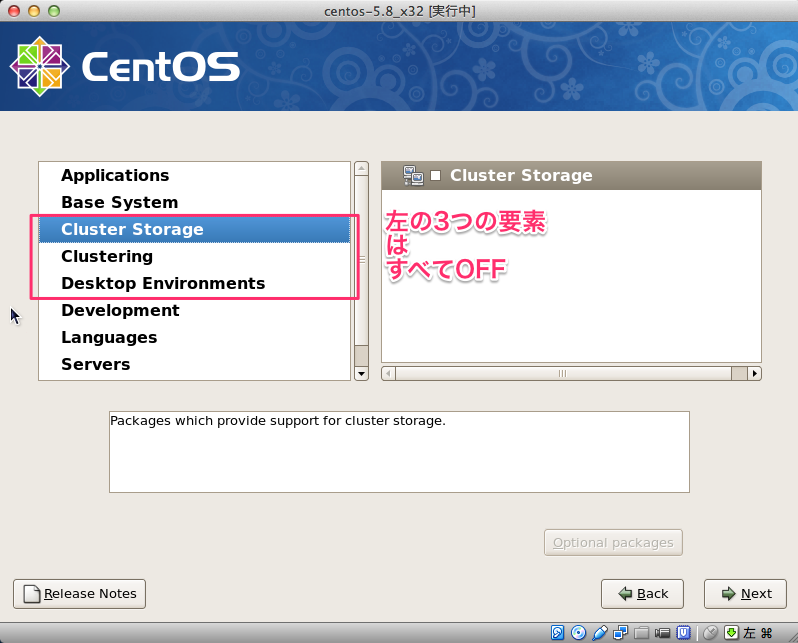
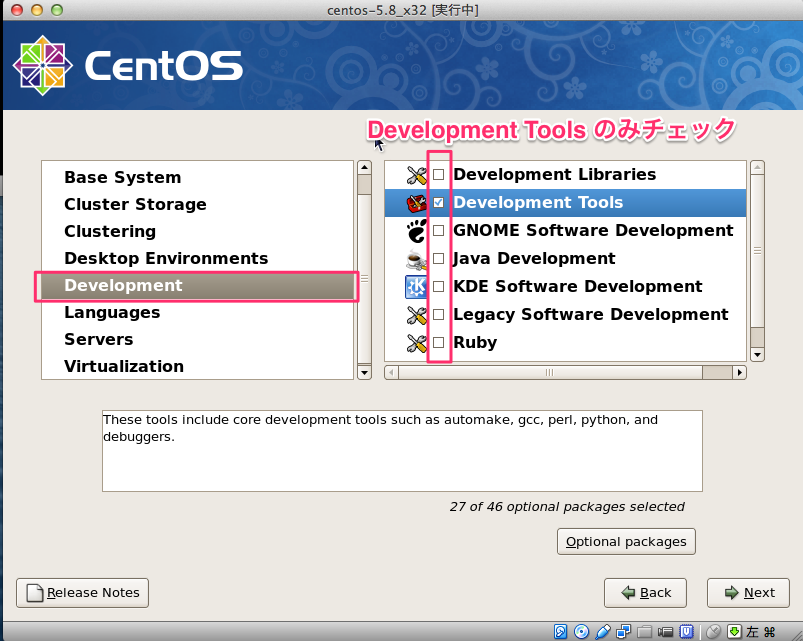
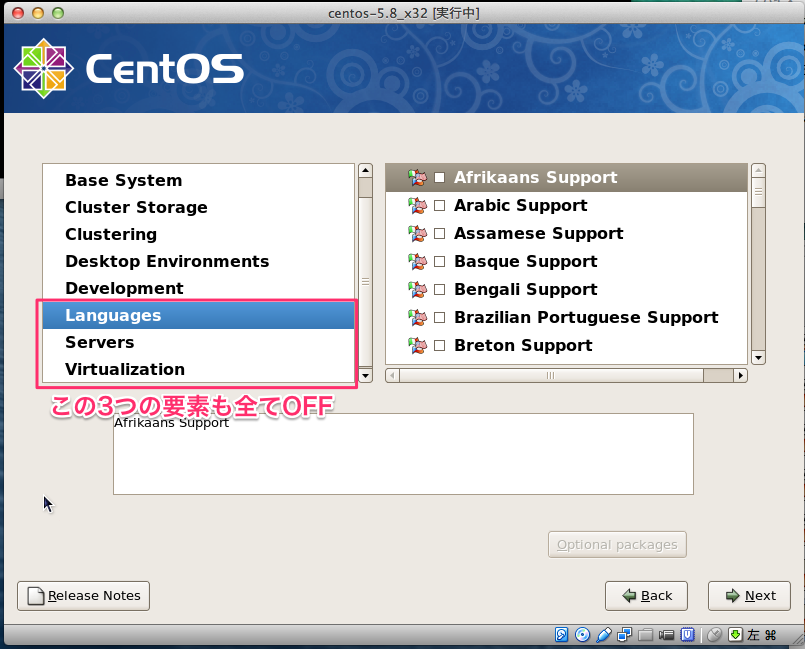
# sed -i -e "s:^ONBOOT=no$:ONBOOT=yes:" /etc/sysconfig/network-scripts/ifcfg-eth0
# cat /etc/sysconfig/network-scripts/ifcfg-eth0 | grep ONBOOT
# service network restart
# ip addr show eth0# ln -f -s /dev/null /etc/udev/rules.d/70-persistent-net.rules
# sed -i -e "s:HWADDR=.*::g" /etc/sysconfig/network-scripts/ifcfg-eth0
# sed -i -e "s:UUID=.*::g" /etc/sysconfig/network-scripts/ifcfg-eth0# sed -i -e "s:^#UseDNS yes:UseDNS no:" /etc/ssh/sshd_config
# service sshd start
# chkconfig sshd onここからの手順は、通常のターミナルからVirtualBoxにアクセスして作業することとする。
$ ssh root@localhost -p 2222# groupadd vagrant
# useradd vagrant -g vagrant -G wheel
# echo "vagrant ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers # sudo設定
# sed -i -e "s:^.*requiretty:#Defaults requiretty:" /etc/sudoers # requiretty を無効# su - vagrant
# mkdir ~/.ssh
# chmod 0700 ~/.ssh
# curl -k -L -o ~/.ssh/authorized_keys https://raw.githubusercontent.com/mitchellh/vagrant/master/keys/vagrant.pub
# chmod 0600 ~/.ssh/authorized_keys# yum install -y wget
# mkdir /media/VBoxGuestAdditions
# wget http://download.virtualbox.org/virtualbox/4.3.18/VBoxGuestAdditions_4.3.18.iso※VirtualBoxのバージョンに合わせてダウンロードしてください。 # mount -o loop,ro VBoxGuestAdditions_4.3.18.iso /media/VBoxGuestAdditions # sh /media/VBoxGuestAdditions/VBoxLinuxAdditions.run
# rm VBoxGuestAdditions_4.3.18.iso
# umount /media/VBoxGuestAdditions
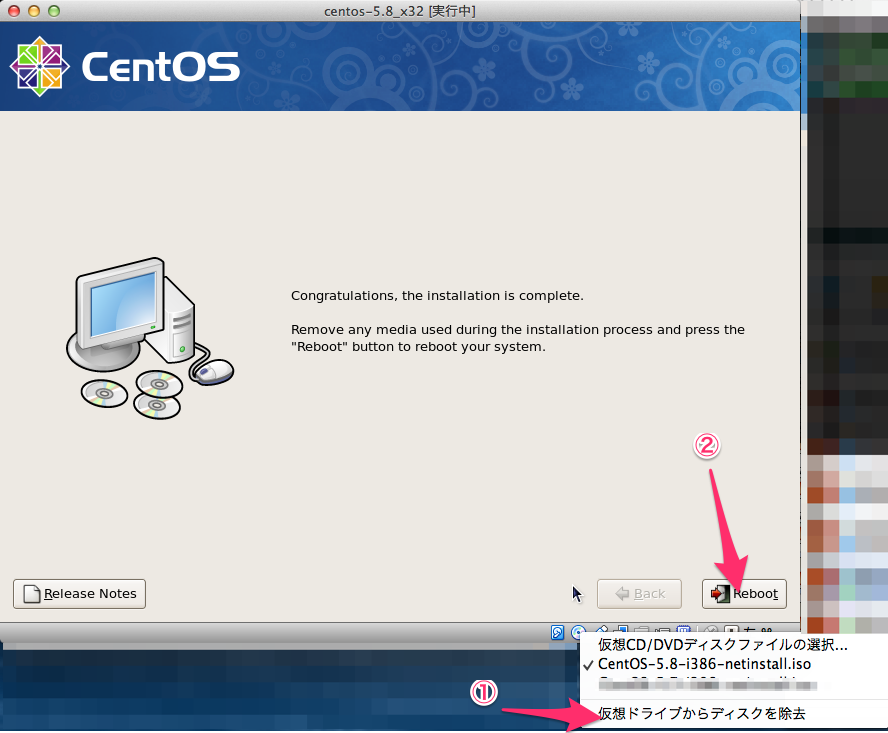
# rmdir /media/VBoxGuestAdditions/# cd ~/VirtualBox\ VMs/centos-5.8_x32/※各自でVirualBoxの保存先は変更してください # vagrant package --base centos-5.8x32 --output centos-5.8x32.box
後は作成したboxを使って
$ vagrant box add centos-5.8_x32 centos-5.8_x32.box
$ vagrant init centos-5.8_x32
$ vagrant upとすればvagrantを使ってCentOS 5.8(32bit)を使用することができます。
今回VMにCentOSをインストールする際にnet-install版を使用しました。実はこれ 4.1 ~ 4.3 の手順をする必要はないかもしれません。また、iptablesで外部からのアクセスが制限されているかもしれませんので、各自でご確認ください。それから、今回CentOS 5.8(32bit)だけでなく、CentOS 5.7(32bit)も欲しかったので、同様の手順でさくさくと作っています。
では、またお会いしましょう(^^)/
突然ですがXFDというものをご存知でしょうか?
オブジェクト倶楽部 http://objectclub.jp/community/xfd/ によると
プロジェクトステータスやメトリクスは、目に見えにくい。見えないからこそ難しい。
そんな悩みを解決してくれるのが、XFD(eXtreme Feedback Device)です。
目に見えて、楽しい、ユニークな装置。目に付いて、絶対見落とさないような装置を指します。安上がりならなおよろし。
とのことです。
例えばCIによるビルドエラーに連動したパトランプ http://gitgear.com/xfd/ など、 そのままだと気づきにくいイベントを気づきやすくするデバイスを指すようです。
今回はそんなXFDをRaspberry Piを利用して作成してみたいと思います。 なお、今回はAtlassian の CIサーバー Atlassian Bamboo を対象としますが、ビルド結果取得の部分だけ替えればJenkinsなどにも対応可能です。
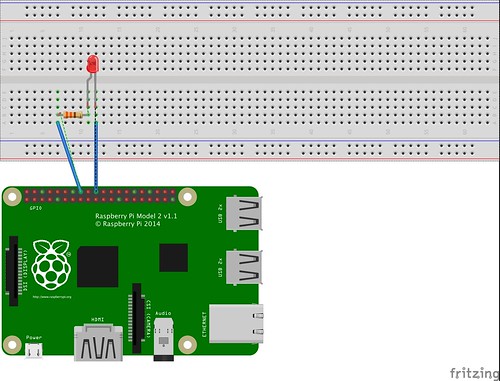
上記のパーツを組み込むとこのようになります。

一応実体配線図も作ってみました。
例えば以下のようにREST APIでBambooのビルド結果を取得します。
なお、今回はBamboo上に複数ブランチが登録されていることを前提としているため、ブランチがないと動きません。
これで、Bambooの指定したブランチがビルドエラーになった際には、 接続されたLEDが点灯するようになりました。

しかし、ちょっとこれでは寂しいので、ひと手間加えたいと思います。
最近はだいぶJOJOや、仮面ライダーに押されているとはいえ、 エンジニアといえばガンダムです。
という訳で、ちょっとガンダム要素を足してみました。
ドリルでモノアイ部分に穴を開けてLEDを装着し、

なるべく目立たないように配線をします。

最近のプラモはよく出来ていて、関節可動部分が多いので、 昔のプラモのように脚部の中がスカスカでなかったのは誤算でした。
今回はちょっと妥協してこのくらいにしておきますが、機会があればもう少し綺麗に配線をしたいと思います。
さて、再度どうなるか試してみます。
万が一Bambooでのビルドが失敗した場合には
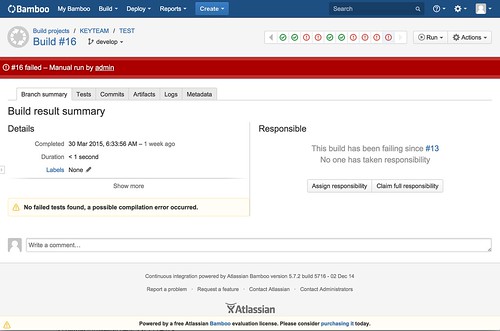
光ります。

これでだいぶ危機感が増しました。
ジムがやられる前になんとしてもビルドエラーを修正しなければなりません!!
Raspberry Piが発売されたことによって、ネットワークを利用した電子工作が簡単にできるようになりました。
電子工作初心者でも簡単に作れるオリジナルのXFDでプロジェクトを活性化して行きましょう!





























