


世の中の名刺管理サービスを使っていたとき、「シンプルな機能なら、わざわざ月額料金を払わなくても、自分でサクッと作れるんじゃないか?」というアイデアが閃きました。
そこで、話題のGemini APIに名刺を読み込んでもらって、名前、会社名等を自動でリスト化する仕組みをDIY(Do It Yourself!)してみました!
なるべく費用が発生しないように
今回はなるべく費用が発生しないように組み立てて行きたいので Google Form (以下、Form) で名刺を登録し、Gemini API で名刺を読み、Google Spreadsheet (以下、Spreadsheet) に記録をしていきます。
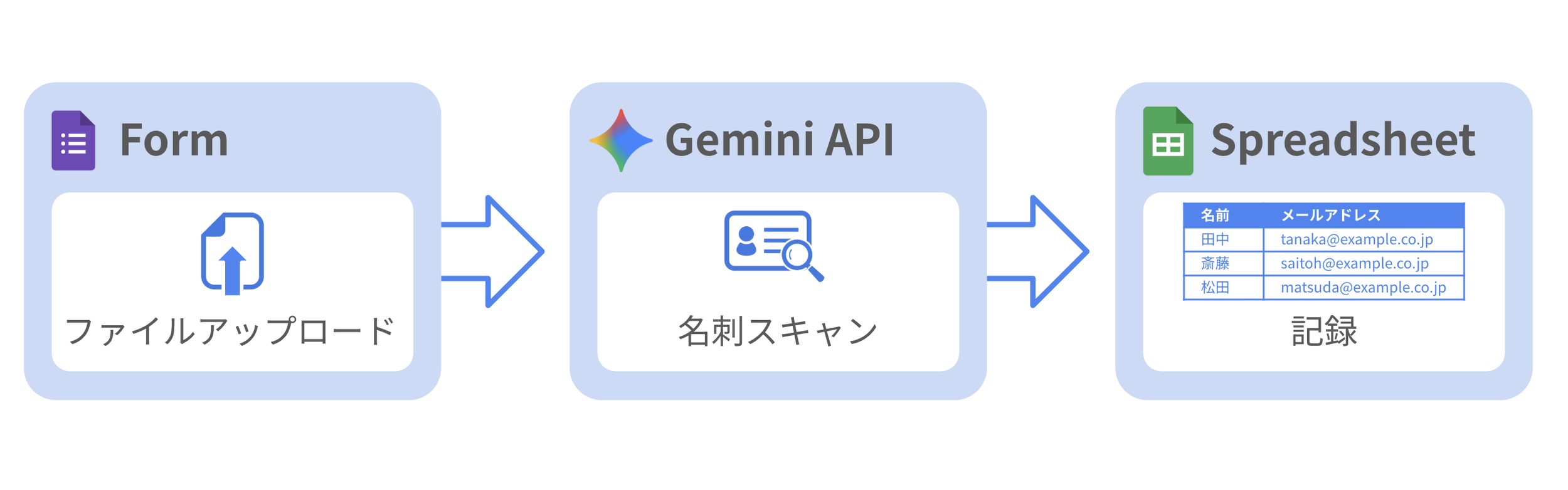
まずは Form を作成
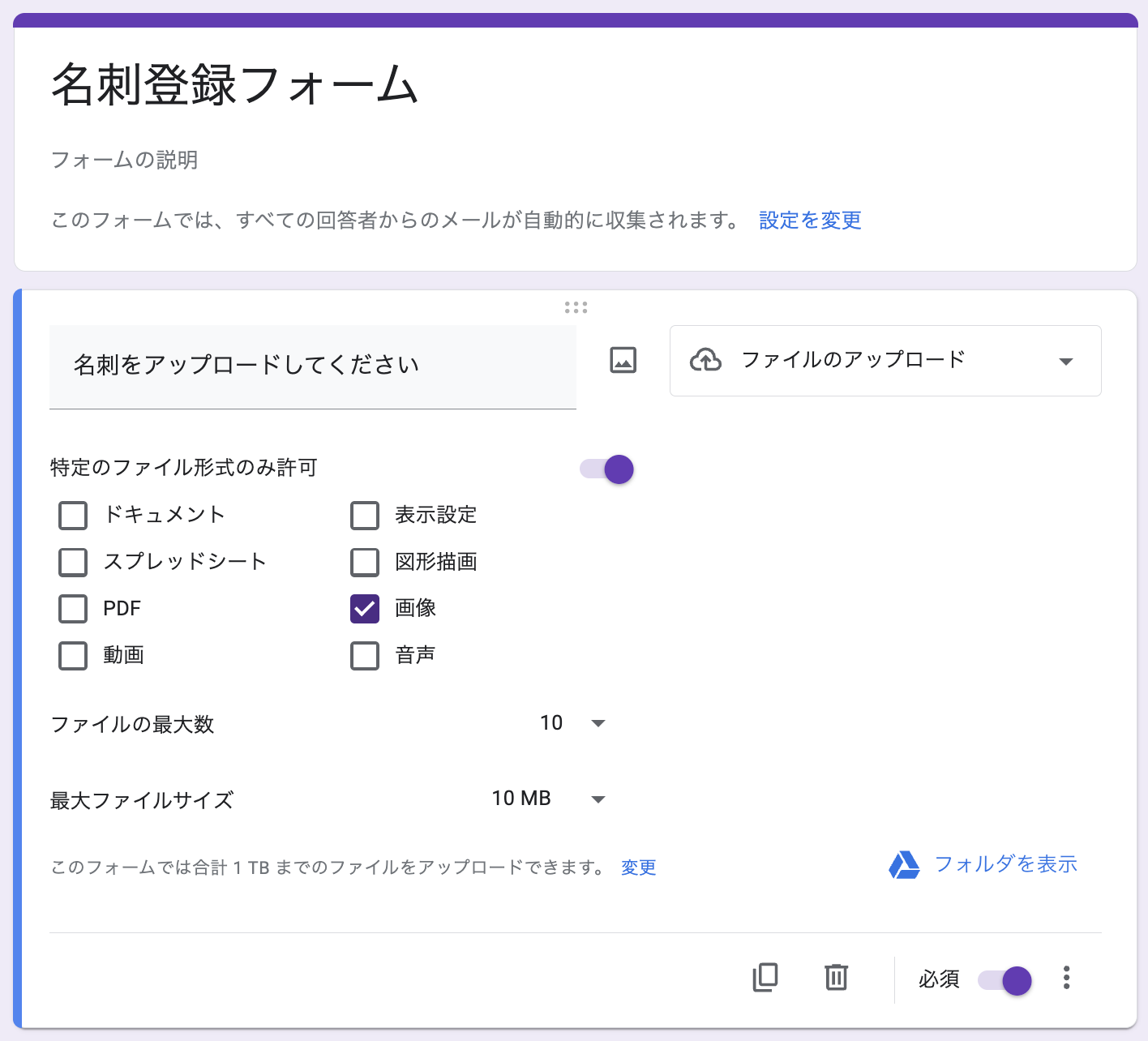
“名刺をアップロードする” 質問を1つ準備します。今回は画像のみを許可し、1度に10枚の画像、最大ファイルサイズを10 MBの設定にします。
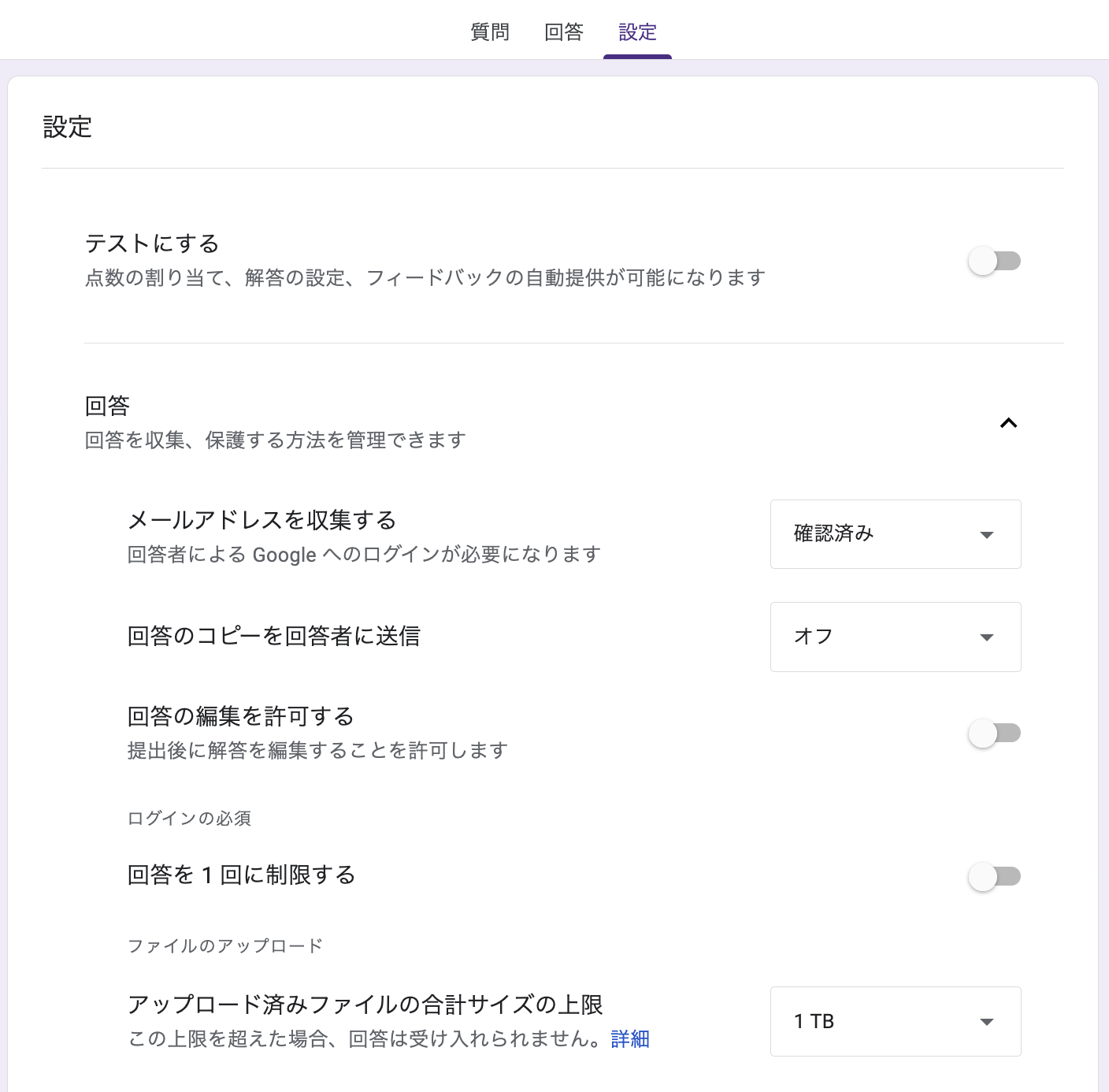
Form の設定で「メールアドレスを収集する」は “確認済み” にします。
質問の作成と設定が完了したら、回答一覧の Spreadsheet を作成し、Google Apps Script の準備もします。

Google Apps Script で Gemini に問い合わせ
Form への投稿をトリガーに Google Apps Script (以下、GAS) を発火させ、GAS から Gemini API を呼び出して Spreadsheet へ記録をします。
Gemini API を利用するには Google Cloud プロジェクトを GAS に紐づける必要があります。Google Cloud のプロジェクトを作成し、Vertex AI API と Google Drive API を有効にしてください。一緒にOAuthの同意画面も設定してください。(Google Drive API は GAS でファイル操作をするので有効にします。)
Vertex AI を利用する場合には、支払い方法が有効な課金アカウントを紐づける必要があります。
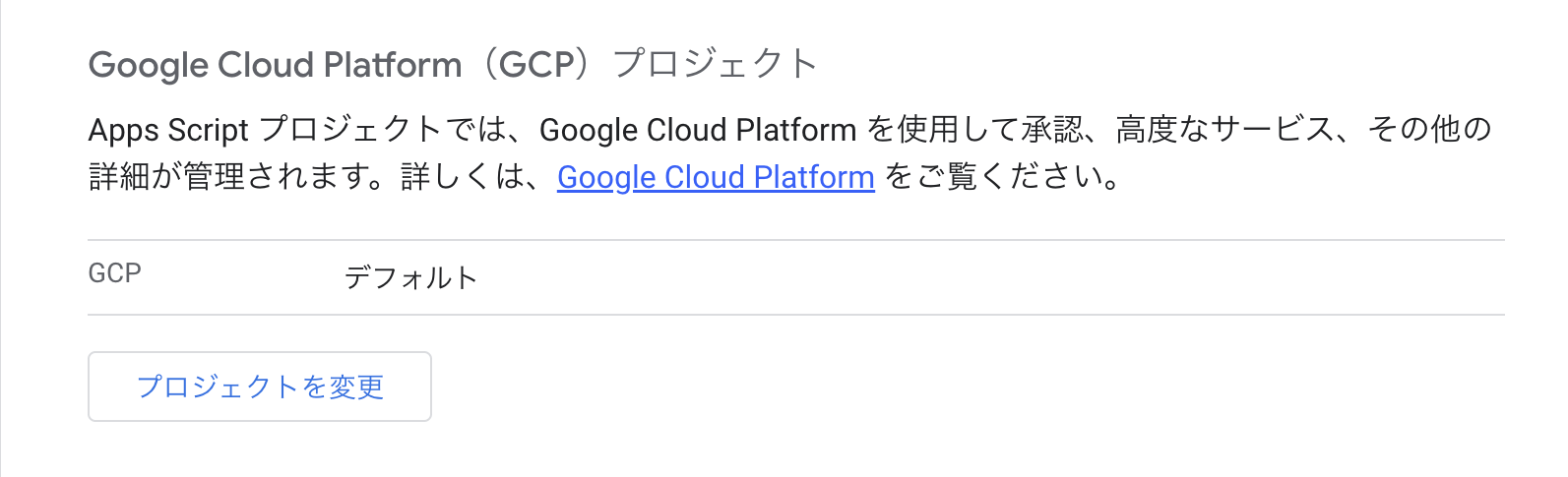
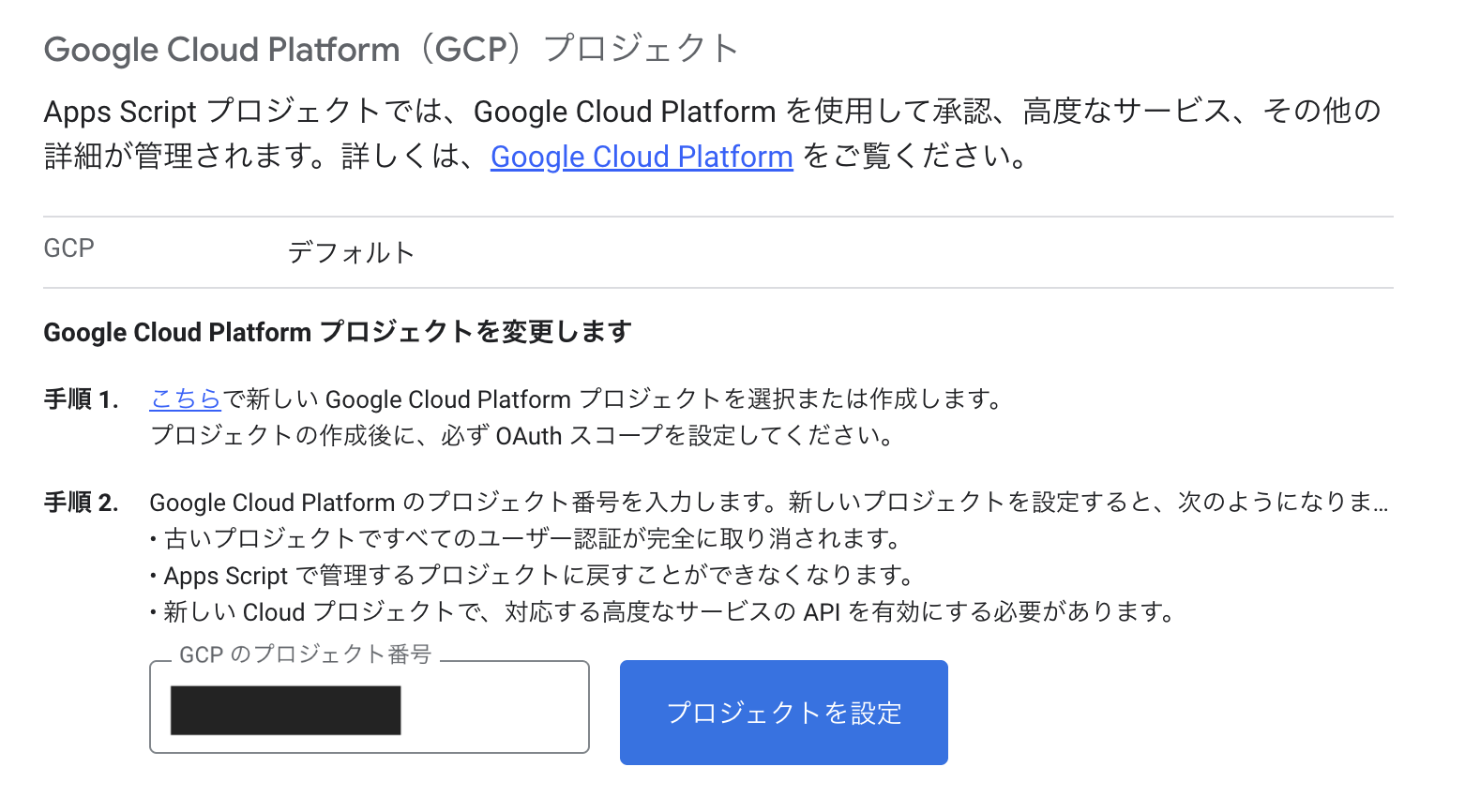
GAS で Google Cloud のプロジェクトを利用できるように設定します。
左メニューの歯車から「Google Cloud Platform(GCP)プロジェクト」の箇所にある “プロジェクトの変更” ボタンをクリック。入力欄が表示されるのでプロジェクト番号 (数字12桁) を入力し “プロジェクト設定” ボタンをクリック。こちらで完了です。
では、フォームから画像を受け取り、Gemini API を呼び出し、Spreadsheet に記録するコードを用意します。
// Google CloudのプロジェクトID
const PROJECT_ID = 'YOUR PROJECT ID';
// データを記録するスプレッドシートのID
const SPREADSHEET_ID = 'YOUR SPREADSHEET ID';
// データを記録するシート名
const SHEET_NAME = '名刺データ';
function onFormSubmit(e) {
try {
const respondentEmail = e.namedValues["メールアドレス"][0];
const fileId = e.namedValues["名刺をアップロードしてください"][0].split("=")[1];
const timestamp = e.namedValues["タイムスタンプ"][0];
const file = DriveApp.getFileById(fileId);
const extractedData = callGeminiApi(file);
writeToSheet(extractedData, file.getUrl(), respondentEmail, timestamp);
} catch (error) {
console.error(`エラーが発生しました: $`);
const sheet = SpreadsheetApp.openById(SPREADSHEET_ID).getSheetByName(SHEET_NAME);
sheet.appendRow([new Date(), 'エラー', error.toString()]);
}
}
function callGeminiApi(file) {
const region = 'us-central1';
const modelId = 'gemini-2.5-flash';
const apiEndpoint = `https://$:generateContent`;
const imageBytes = file.getBlob().getBytes();
const base64Image = Utilities.base64Encode(imageBytes);
const payload = {
"contents": [{
"role": "user",
"parts": [
{ "text": "この名刺画像から以下の情報を抽出し、必ずJSON形式で回答してください。存在しない情報は必ず空文字(\"\")としてください。\n- 氏名 (name)\n- 会社名 (company)\n- 部署名 (department)\n- 役職 (title)\n- メールアドレス (email)\n- 電話番号 (phone)\n- 住所 (address)" },
{ "inline_data": { "mime_type": file.getMimeType(), "data": base64Image } }
]
}]
};
const token = ScriptApp.getOAuthToken();
const options = {
'method': 'post',
'contentType': 'application/json',
'payload': JSON.stringify(payload),
'headers': {'Authorization': 'Bearer ' + token},
'muteHttpExceptions': true
};
const response = UrlFetchApp.fetch(apiEndpoint, options);
const responseBody = response.getContentText();
const jsonResponse = JSON.parse(responseBody);
if (jsonResponse.candidates[0].content.parts[0].text) {
let textData = jsonResponse.candidates[0].content.parts[0].text;
textData = textData.replace(/```json/g, '').replace(/```/g, '').trim();
return JSON.parse(textData);
} else {
console.error('Geminiからの有効な回答がありませんでした。');
console.warn(responseBody);
throw new Error('Geminiからの有効な回答がありませんでした。');
}
}
function writeToSheet(data, fileUrl, postedUserEmail, timestamp) {
const sheet = SpreadsheetApp.openById(SPREADSHEET_ID).getSheetByName(SHEET_NAME);
// ヘッダーに対応する順序でデータを配列に格納
const newRow = [
timestamp,
postedUserEmail,
data.name || '',
data.company || '',
data.department || '',
data.title || '',
data.email || '',
data.phone || '',
data.address || '',
fileUrl
];
sheet.appendRow(newRow);
}
注意)コード先頭にある PROJECT_ID と SPREADSHEET_ID はあなた自身のものに変更してください。
Google Apps Script のトリガー設定
コードが準備できたので、あとは Form への送信をトリガーに実行されるようにします。
左メニューの 時計アイコン(トリガー) からトリガーを追加します。
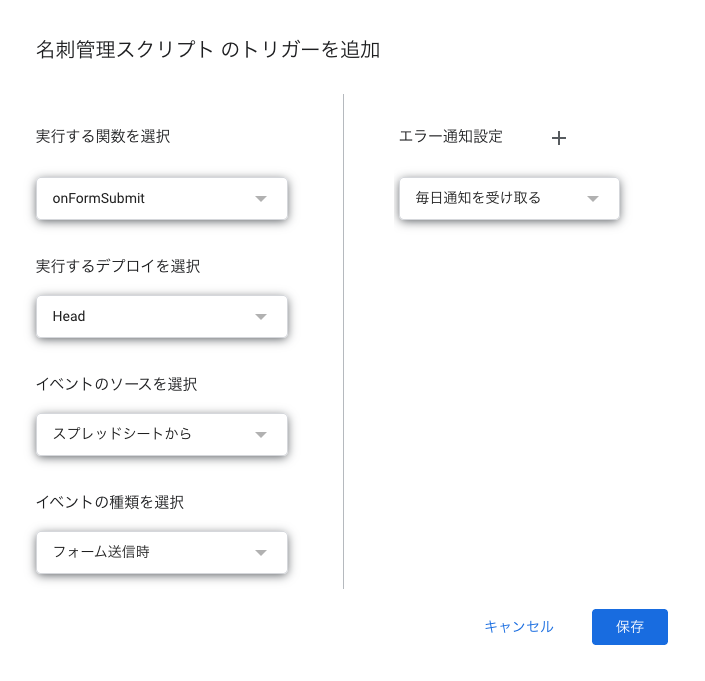
Let’s Try
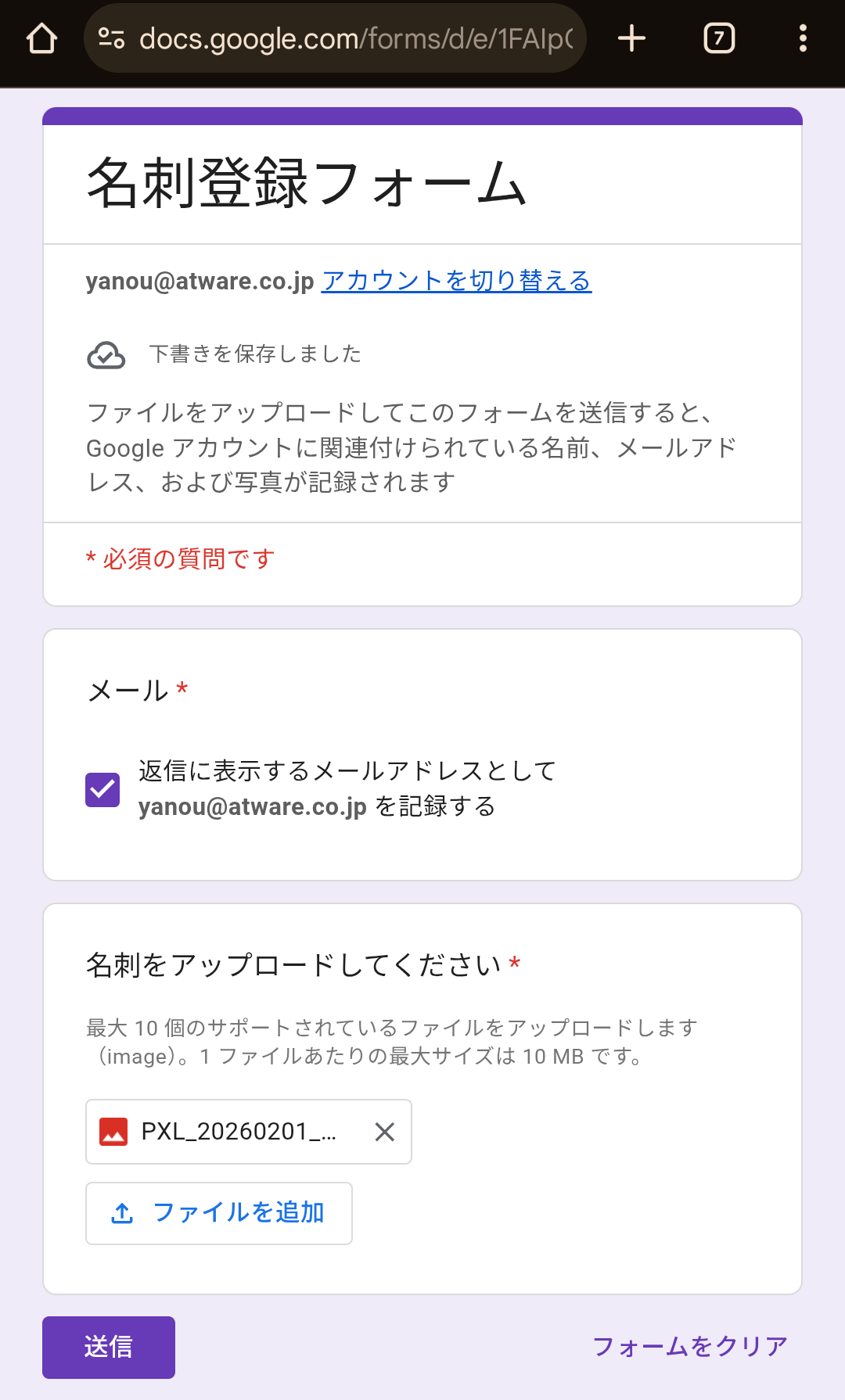
では準備ができたので実際に試してみましょう。スマホで Form の回答リンクにアクセスします。
今回は筆者の名刺を読み取って試してみましょう。

結果が記録されているスプレッドシートを見てみましょう。


無事に名刺の内容を読み取れていますね!
最後に
今回は Google Form で名刺をアップロードし、Google Apps Script 経由で Gemini API (Vertex AI) を活用して内容を読み、Google Spreadsheet に記録する方法をご紹介しました。複雑な開発が必要なくGoogleが提供するサービスを活用することで、普段当たり前に使っているサービスを作成することできます。
もしかしたら「あれもできるのでは?」「私も試してみたいけど間違っていないか見てもらいたい」などあればお気軽にお問い合わせください。































